 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer for Image Quality Assessment
Paper and Code


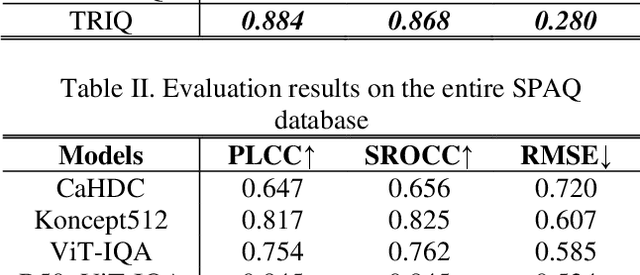

Transformer has become the new standard method in natural language processing (NLP), and it also attracts research interests in computer vision area. In this paper we investigate the application of Transformer in Image Quality (TRIQ) assessment. Following the original Transformer encoder employed in Vision Transformer (ViT), we propose an architecture of using a shallow Transformer encoder on the top of a feature map extracted by convolution neural networks (CNN). Adaptive positional embedding is employed in the Transformer encoder to handle images with arbitrary resolutions. Different settings of Transformer architectures have been investigated on publicly available image quality databases. We have found that the proposed TRIQ architecture achieves outstanding performance. The implementation of TRIQ is published on Github (https://github.com/junyongyou/triq).