 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHalf of an image is enough for quality assessment
Feb 09, 2023Deep networks have demonstrated promising results in the field of Image Quality Assessment (IQA). However, there has been limited research on understanding how deep models in IQA work. This study introduces a novel positional masked transformer for IQA and provides insights into the contribution of different regions of an image towards its overall quality. Results indicate that half of an image may play a trivial role in determining image quality, while the other half is critical. This observation is extended to several other CNN-based IQA models, revealing that half of the image regions can significantly impact the overall image quality. To further enhance our understanding, three semantic measures (saliency, frequency, and objectness) were derived and found to have high correlation with the importance of image regions in IQA.
Apples and Oranges? Assessing Image Quality over Content Recognition
Jan 31, 2023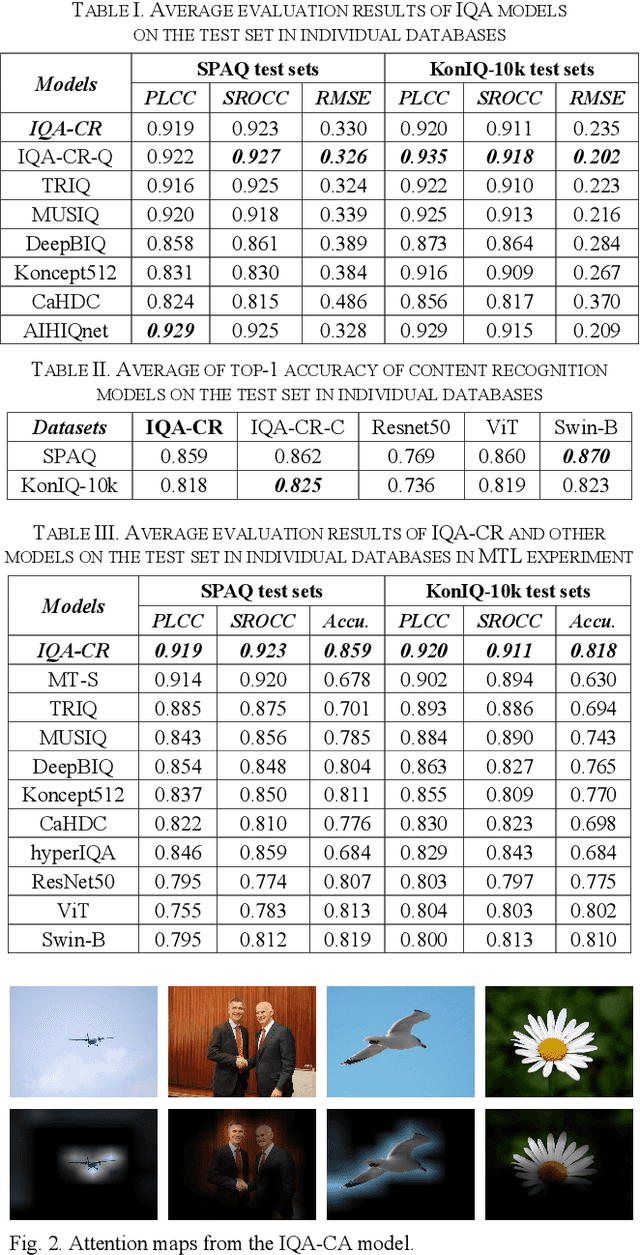
Image recognition and quality assessment are two important viewing tasks, while potentially following different visual mechanisms. This paper investigates if the two tasks can be performed in a multitask learning manner. A sequential spatial-channel attention module is proposed to simulate the visual attention and contrast sensitivity mechanisms that are crucial for content recognition and quality assessment. Spatial attention is shared between content recognition and quality assessment, while channel attention is solely for quality assessment. Such attention module is integrated into Transformer to build a uniform model for the two viewing tasks. The experimental results have demonstrated that the proposed uniform model can achieve promising performance for both quality assessment and content recognition tasks.
Visual Mechanisms Inspired Efficient Transformers for Image and Video Quality Assessment
Apr 06, 2022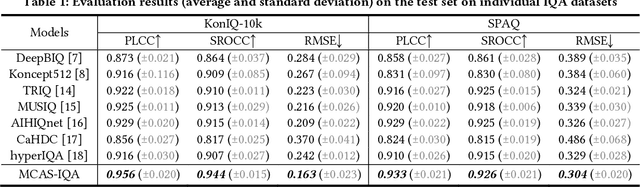

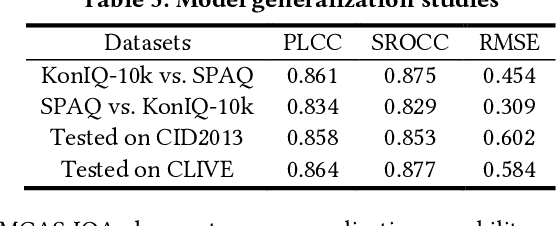
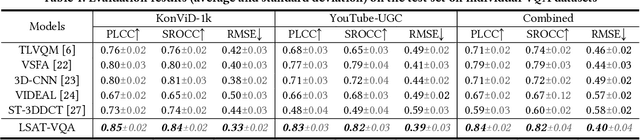
Visual (image, video) quality assessments can be modelled by visual features in different domains, e.g., spatial, frequency, and temporal domains. Perceptual mechanisms in the human visual system (HVS) play a crucial role in generation of quality perception. This paper proposes a general framework for no-reference visual quality assessment using efficient windowed transformer architectures. A lightweight module for multi-stage channel attention is integrated into Swin (shifted window) Transformer. Such module can represent appropriate perceptual mechanisms in image quality assessment (IQA) to build an accurate IQA model. Meanwhile, representative features for image quality perception in the spatial and frequency domains can also be derived from the IQA model, which are then fed into another windowed transformer architecture for video quality assessment (VQA). The VQA model efficiently reuses attention information across local windows to tackle the issue of expensive time and memory complexities of original transformer. Experimental results on both large-scale IQA and VQA databases demonstrate that the proposed quality assessment models outperform other state-of-the-art models by large margins. The complete source code will be published on Github.
Consumer Image Quality Prediction using Recurrent Neural Networks for Spatial Pooling
Jun 02, 2021
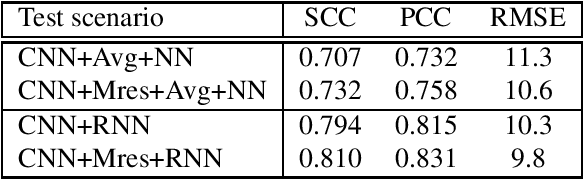


Promising results for subjective image quality prediction have been achieved during the past few years by using convolutional neural networks (CNN). However, the use of CNNs for high resolution image quality assessment remains a challenge, since typical CNN architectures have been designed for small resolution input images. In this study, we propose an image quality model that attempts to mimic the attention mechanism of human visual system (HVS) by using a recurrent neural network (RNN) for spatial pooling of the features extracted from different spatial areas (patches) by a deep CNN-based feature extractor. The experimental study, conducted by using images with different resolutions from two recently published image quality datasets, indicates that the quality prediction accuracy of the proposed method is competitive against benchmark models representing the state-of-the-art, and the proposed method also performs consistently on different resolution versions of the same dataset.
Transformer for Image Quality Assessment
Jan 08, 2021

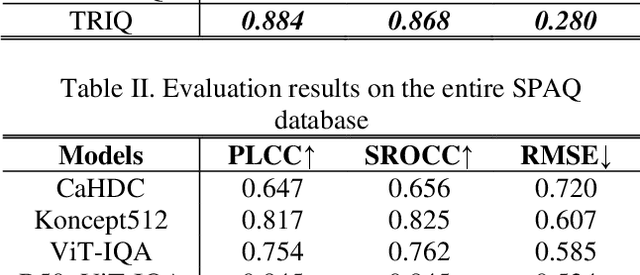

Transformer has become the new standard method in natural language processing (NLP), and it also attracts research interests in computer vision area. In this paper we investigate the application of Transformer in Image Quality (TRIQ) assessment. Following the original Transformer encoder employed in Vision Transformer (ViT), we propose an architecture of using a shallow Transformer encoder on the top of a feature map extracted by convolution neural networks (CNN). Adaptive positional embedding is employed in the Transformer encoder to handle images with arbitrary resolutions. Different settings of Transformer architectures have been investigated on publicly available image quality databases. We have found that the proposed TRIQ architecture achieves outstanding performance. The implementation of TRIQ is published on Github (https://github.com/junyongyou/triq).