 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApples and Oranges? Assessing Image Quality over Content Recognition
Paper and Code
Jan 31, 2023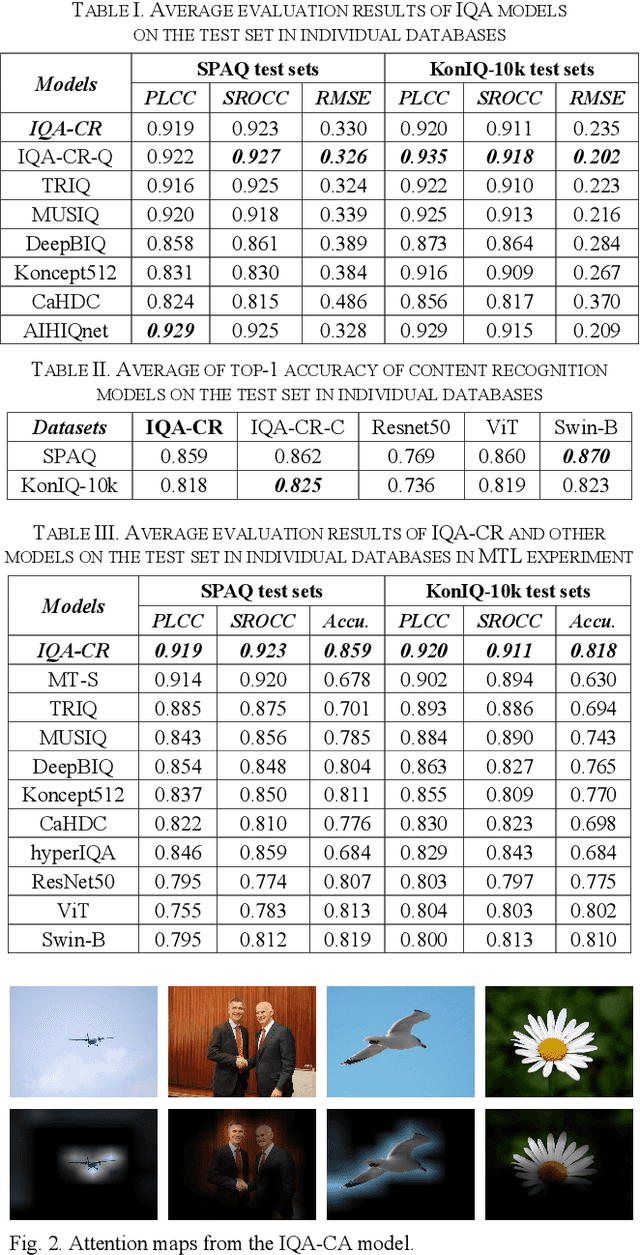
Image recognition and quality assessment are two important viewing tasks, while potentially following different visual mechanisms. This paper investigates if the two tasks can be performed in a multitask learning manner. A sequential spatial-channel attention module is proposed to simulate the visual attention and contrast sensitivity mechanisms that are crucial for content recognition and quality assessment. Spatial attention is shared between content recognition and quality assessment, while channel attention is solely for quality assessment. Such attention module is integrated into Transformer to build a uniform model for the two viewing tasks. The experimental results have demonstrated that the proposed uniform model can achieve promising performance for both quality assessment and content recognition tasks.