 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImprove Student's Reasoning Generalizability through Cascading Decomposed CoTs Distillation
May 30, 2024Large language models (LLMs) exhibit enhanced reasoning at larger scales, driving efforts to distill these capabilities into smaller models via teacher-student learning. Previous works simply fine-tune student models on teachers' generated Chain-of-Thoughts (CoTs) data. Although these methods enhance in-domain (IND) reasoning performance, they struggle to generalize to out-of-domain (OOD) tasks. We believe that the widespread spurious correlations between questions and answers may lead the model to preset a specific answer which restricts the diversity and generalizability of its reasoning process. In this paper, we propose Cascading Decomposed CoTs Distillation (CasCoD) to address these issues by decomposing the traditional single-step learning process into two cascaded learning steps. Specifically, by restructuring the training objectives -- removing the answer from outputs and concatenating the question with the rationale as input -- CasCoD's two-step learning process ensures that students focus on learning rationales without interference from the preset answers, thus improving reasoning generalizability. Extensive experiments demonstrate the effectiveness of CasCoD on both IND and OOD benchmark reasoning datasets. Code can be found at https://github.com/C-W-D/CasCoD.
Beyond Imitation: Learning Key Reasoning Steps from Dual Chain-of-Thoughts in Reasoning Distillation
May 30, 2024



As Large Language Models (LLMs) scale up and gain powerful Chain-of-Thoughts (CoTs) reasoning abilities, practical resource constraints drive efforts to distill these capabilities into more compact Smaller Language Models (SLMs). We find that CoTs consist mainly of simple reasoning forms, with a small proportion ($\approx 4.7\%$) of key reasoning steps that truly impact conclusions. However, previous distillation methods typically involve supervised fine-tuning student SLMs only on correct CoTs data produced by teacher LLMs, resulting in students struggling to learn the key reasoning steps, instead imitating the teacher's reasoning forms and making errors or omissions on these steps. To address these issues, drawing an analogy to human learning, where analyzing mistakes according to correct solutions often reveals the crucial steps leading to successes or failures, we propose mistak\textbf{E}-\textbf{D}riven key reason\textbf{I}ng step distilla\textbf{T}ion (\textbf{EDIT}), a novel method that further aids SLMs learning key reasoning steps rather than mere simple fine-tuning. Firstly, to expose these crucial steps in CoTs, we design specific prompts to generate dual CoTs data with similar reasoning paths but divergent conclusions. Then, we apply the minimum edit distance algorithm on the dual CoTs data to locate these key steps and optimize the likelihood of these steps. Extensive experiments validate the effectiveness of EDIT across both in-domain and out-of-domain benchmark reasoning datasets. Further analysis shows that EDIT can generate high-quality CoTs with more correct key reasoning steps. Notably, we also explore how different mistake patterns affect performance and find that EDIT benefits more from logical errors than from knowledge or mathematical calculation errors in dual CoTs\footnote{Code can be found at \url{https://github.com/C-W-D/EDIT}}.
CT-GAT: Cross-Task Generative Adversarial Attack based on Transferability
Nov 05, 2023
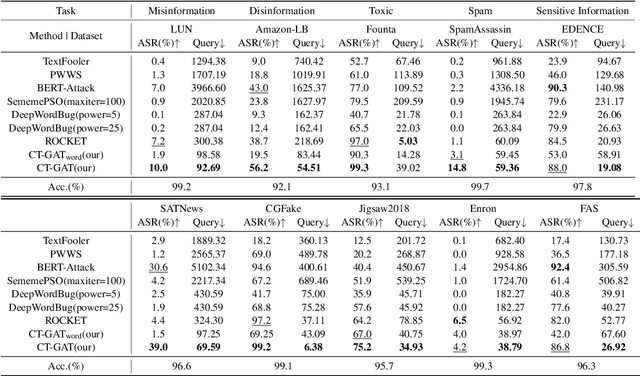
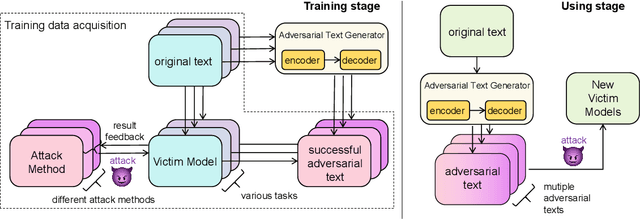

Neural network models are vulnerable to adversarial examples, and adversarial transferability further increases the risk of adversarial attacks. Current methods based on transferability often rely on substitute models, which can be impractical and costly in real-world scenarios due to the unavailability of training data and the victim model's structural details. In this paper, we propose a novel approach that directly constructs adversarial examples by extracting transferable features across various tasks. Our key insight is that adversarial transferability can extend across different tasks. Specifically, we train a sequence-to-sequence generative model named CT-GAT using adversarial sample data collected from multiple tasks to acquire universal adversarial features and generate adversarial examples for different tasks. We conduct experiments on ten distinct datasets, and the results demonstrate that our method achieves superior attack performance with small cost.
MeaeQ: Mount Model Extraction Attacks with Efficient Queries
Oct 21, 2023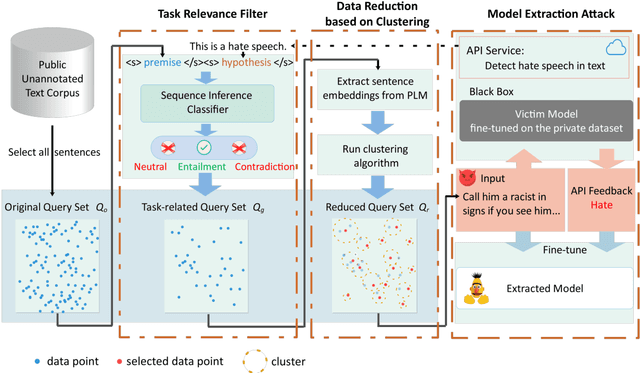
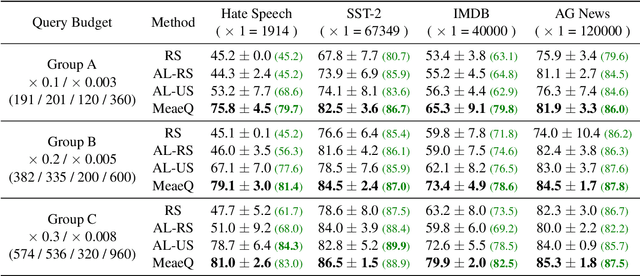
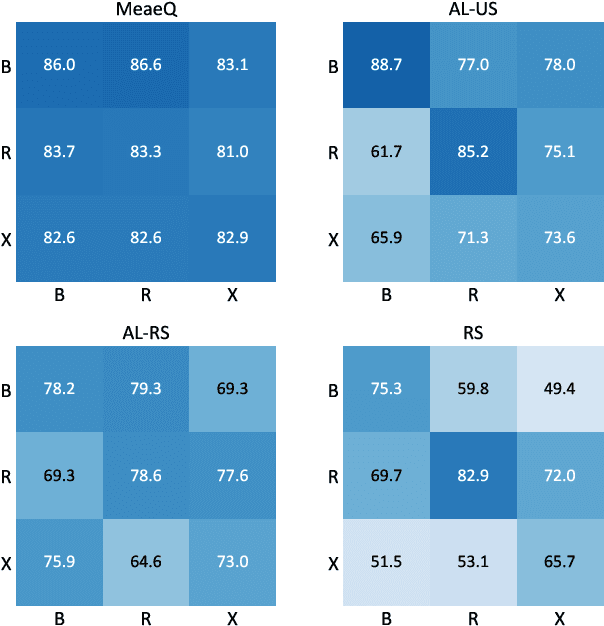

We study model extraction attacks in natural language processing (NLP) where attackers aim to steal victim models by repeatedly querying the open Application Programming Interfaces (APIs). Recent works focus on limited-query budget settings and adopt random sampling or active learning-based sampling strategies on publicly available, unannotated data sources. However, these methods often result in selected queries that lack task relevance and data diversity, leading to limited success in achieving satisfactory results with low query costs. In this paper, we propose MeaeQ (Model extraction attack with efficient Queries), a straightforward yet effective method to address these issues. Specifically, we initially utilize a zero-shot sequence inference classifier, combined with API service information, to filter task-relevant data from a public text corpus instead of a problem domain-specific dataset. Furthermore, we employ a clustering-based data reduction technique to obtain representative data as queries for the attack. Extensive experiments conducted on four benchmark datasets demonstrate that MeaeQ achieves higher functional similarity to the victim model than baselines while requiring fewer queries. Our code is available at https://github.com/C-W-D/MeaeQ.