 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Geometric Deep Learning Meets Pretrained Protein Language Models
Dec 07, 2022Geometric deep learning has recently achieved great success in non-Euclidean domains, and learning on 3D structures of large biomolecules is emerging as a distinct research area. However, its efficacy is largely constrained due to the limited quantity of structural data. Meanwhile, protein language models trained on substantial 1D sequences have shown burgeoning capabilities with scale in a broad range of applications. Nevertheless, no preceding studies consider combining these different protein modalities to promote the representation power of geometric neural networks. To address this gap, we make the foremost step to integrate the knowledge learned by well-trained protein language models into several state-of-the-art geometric networks. Experiments are evaluated on a variety of protein representation learning benchmarks, including protein-protein interface prediction, model quality assessment, protein-protein rigid-body docking, and binding affinity prediction, leading to an overall improvement of 20% over baselines and the new state-of-the-art performance. Strong evidence indicates that the incorporation of protein language models' knowledge enhances geometric networks' capacity by a significant margin and can be generalized to complex tasks.
Adaptive Interaction Modeling via Graph Operations Search
May 05, 2020
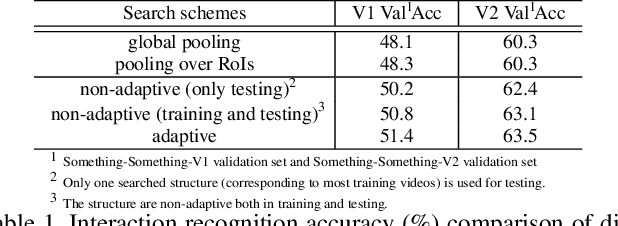


Interaction modeling is important for video action analysis. Recently, several works design specific structures to model interactions in videos. However, their structures are manually designed and non-adaptive, which require structures design efforts and more importantly could not model interactions adaptively. In this paper, we automate the process of structures design to learn adaptive structures for interaction modeling. We propose to search the network structures with differentiable architecture search mechanism, which learns to construct adaptive structures for different videos to facilitate adaptive interaction modeling. To this end, we first design the search space with several basic graph operations that explicitly capture different relations in videos. We experimentally demonstrate that our architecture search framework learns to construct adaptive interaction modeling structures, which provides more understanding about the relations between the structures and some interaction characteristics, and also releases the requirement of structures design efforts. Additionally, we show that the designed basic graph operations in the search space are able to model different interactions in videos. The experiments on two interaction datasets show that our method achieves competitive performance with state-of-the-arts.