 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranslator2Vec: Understanding and Representing Human Post-Editors
Paper and Code
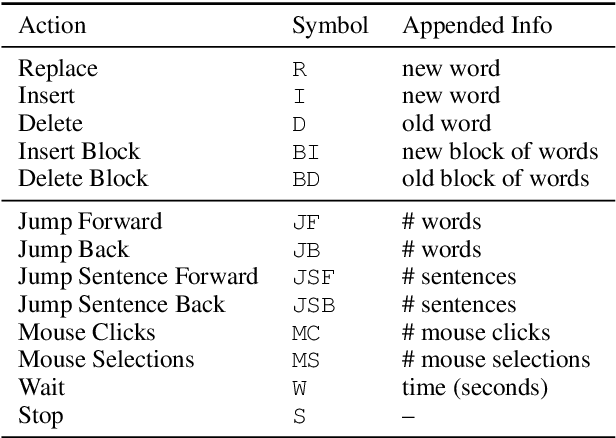
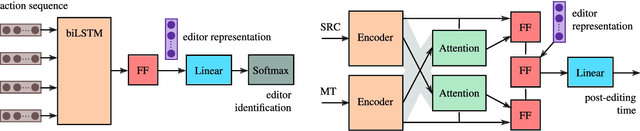

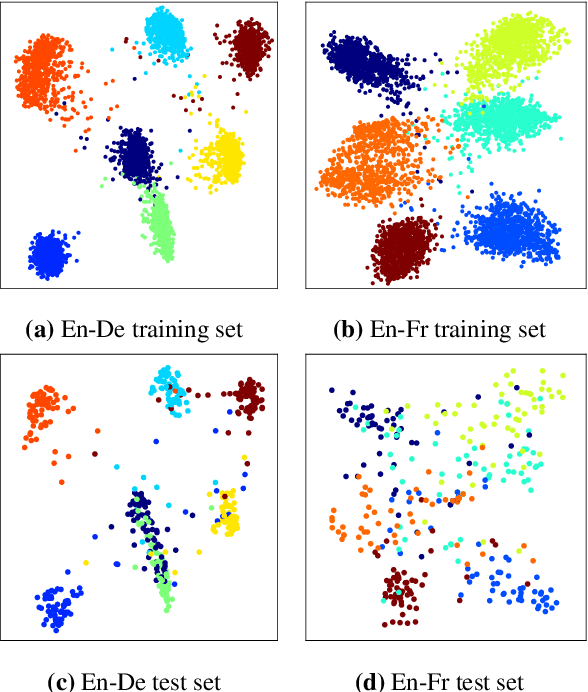
The combination of machines and humans for translation is effective, with many studies showing productivity gains when humans post-edit machine-translated output instead of translating from scratch. To take full advantage of this combination, we need a fine-grained understanding of how human translators work, and which post-editing styles are more effective than others. In this paper, we release and analyze a new dataset with document-level post-editing action sequences, including edit operations from keystrokes, mouse actions, and waiting times. Our dataset comprises 66,268 full document sessions post-edited by 332 humans, the largest of the kind released to date. We show that action sequences are informative enough to identify post-editors accurately, compared to baselines that only look at the initial and final text. We build on this to learn and visualize continuous representations of post-editors, and we show that these representations improve the downstream task of predicting post-editing time.