 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Explainable Evaluation Metrics for Natural Language Generation
Paper and Code
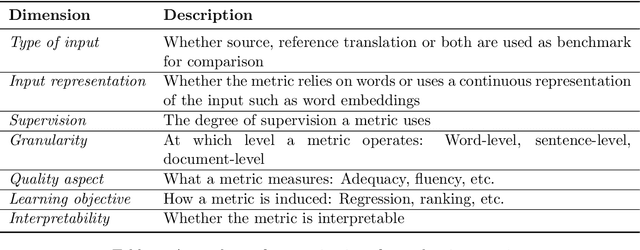
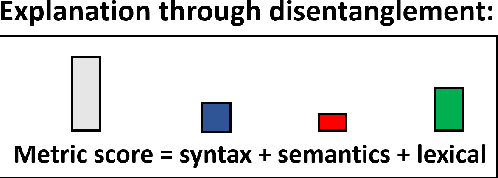
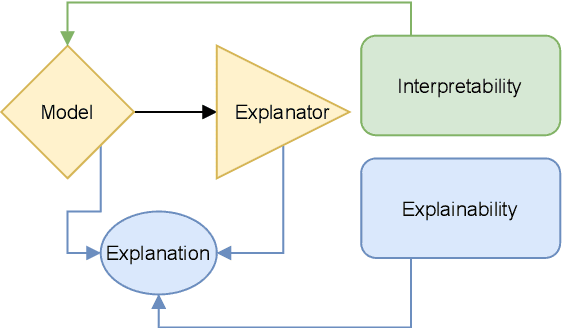

Unlike classical lexical overlap metrics such as BLEU, most current evaluation metrics (such as BERTScore or MoverScore) are based on black-box language models such as BERT or XLM-R. They often achieve strong correlations with human judgments, but recent research indicates that the lower-quality classical metrics remain dominant, one of the potential reasons being that their decision processes are transparent. To foster more widespread acceptance of the novel high-quality metrics, explainability thus becomes crucial. In this concept paper, we identify key properties and propose key goals of explainable machine translation evaluation metrics. We also provide a synthesizing overview over recent approaches for explainable machine translation metrics and discuss how they relate to those goals and properties. Further, we conduct own novel experiments, which (among others) find that current adversarial NLP techniques are unsuitable for automatically identifying limitations of high-quality black-box evaluation metrics, as they are not meaning-preserving. Finally, we provide a vision of future approaches to explainable evaluation metrics and their evaluation. We hope that our work can help catalyze and guide future research on explainable evaluation metrics and, mediately, also contribute to better and more transparent text generation systems.