 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModelling Commonsense Commonalities with Multi-Facet Concept Embeddings
Mar 25, 2024Concept embeddings offer a practical and efficient mechanism for injecting commonsense knowledge into downstream tasks. Their core purpose is often not to predict the commonsense properties of concepts themselves, but rather to identify commonalities, i.e.\ sets of concepts which share some property of interest. Such commonalities are the basis for inductive generalisation, hence high-quality concept embeddings can make learning easier and more robust. Unfortunately, standard embeddings primarily reflect basic taxonomic categories, making them unsuitable for finding commonalities that refer to more specific aspects (e.g.\ the colour of objects or the materials they are made of). In this paper, we address this limitation by explicitly modelling the different facets of interest when learning concept embeddings. We show that this leads to embeddings which capture a more diverse range of commonsense properties, and consistently improves results in downstream tasks such as ultra-fine entity typing and ontology completion.
Distilling Semantic Concept Embeddings from Contrastively Fine-Tuned Language Models
May 16, 2023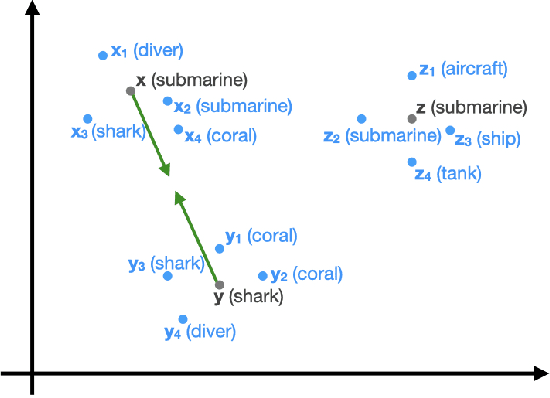


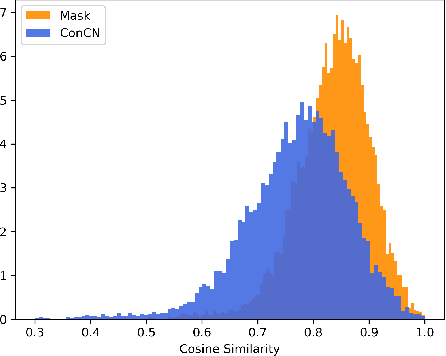
Learning vectors that capture the meaning of concepts remains a fundamental challenge. Somewhat surprisingly, perhaps, pre-trained language models have thus far only enabled modest improvements to the quality of such concept embeddings. Current strategies for using language models typically represent a concept by averaging the contextualised representations of its mentions in some corpus. This is potentially sub-optimal for at least two reasons. First, contextualised word vectors have an unusual geometry, which hampers downstream tasks. Second, concept embeddings should capture the semantic properties of concepts, whereas contextualised word vectors are also affected by other factors. To address these issues, we propose two contrastive learning strategies, based on the view that whenever two sentences reveal similar properties, the corresponding contextualised vectors should also be similar. One strategy is fully unsupervised, estimating the properties which are expressed in a sentence from the neighbourhood structure of the contextualised word embeddings. The second strategy instead relies on a distant supervision signal from ConceptNet. Our experimental results show that the resulting vectors substantially outperform existing concept embeddings in predicting the semantic properties of concepts, with the ConceptNet-based strategy achieving the best results. These findings are furthermore confirmed in a clustering task and in the downstream task of ontology completion.