 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating LSTM and BERT for Long-Sequence Data Analysis in Intelligent Tutoring Systems
Paper and Code
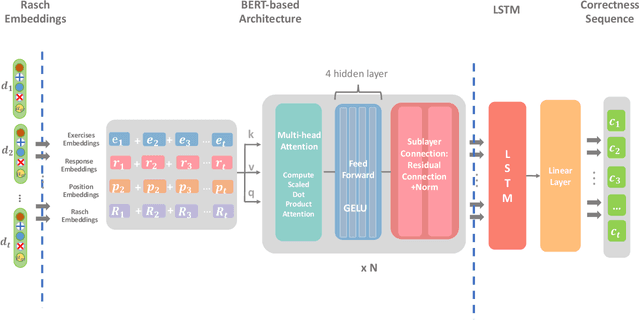
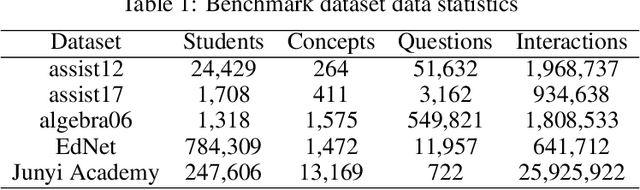
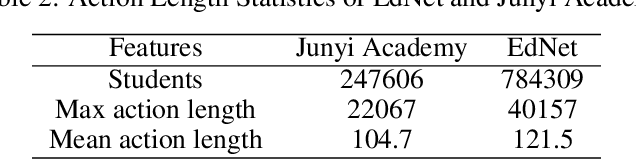
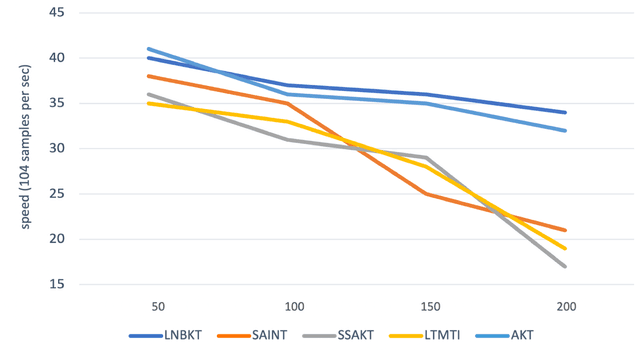
The field of Knowledge Tracing aims to understand how students learn and master knowledge over time by analyzing their historical behaviour data. To achieve this goal, many researchers have proposed Knowledge Tracing models that use data from Intelligent Tutoring Systems to predict students' subsequent actions. However, with the development of Intelligent Tutoring Systems, large-scale datasets containing long-sequence data began to emerge. Recent deep learning based Knowledge Tracing models face obstacles such as low efficiency, low accuracy, and low interpretability when dealing with large-scale datasets containing long-sequence data. To address these issues and promote the sustainable development of Intelligent Tutoring Systems, we propose a LSTM BERT-based Knowledge Tracing model for long sequence data processing, namely LBKT, which uses a BERT-based architecture with a Rasch model-based embeddings block to deal with different difficulty levels information and an LSTM block to process the sequential characteristic in students' actions. LBKT achieves the best performance on most benchmark datasets on the metrics of ACC and AUC. Additionally, an ablation study is conducted to analyse the impact of each component of LBKT's overall performance. Moreover, we used t-SNE as the visualisation tool to demonstrate the model's embedding strategy. The results indicate that LBKT is faster, more interpretable, and has a lower memory cost than the traditional deep learning based Knowledge Tracing methods.