 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHMCF: A Human-in-the-loop Multi-Robot Collaboration Framework Based on Large Language Models
May 01, 2025Rapid advancements in artificial intelligence (AI) have enabled robots to performcomplex tasks autonomously with increasing precision. However, multi-robot systems (MRSs) face challenges in generalization, heterogeneity, and safety, especially when scaling to large-scale deployments like disaster response. Traditional approaches often lack generalization, requiring extensive engineering for new tasks and scenarios, and struggle with managing diverse robots. To overcome these limitations, we propose a Human-in-the-loop Multi-Robot Collaboration Framework (HMCF) powered by large language models (LLMs). LLMs enhance adaptability by reasoning over diverse tasks and robot capabilities, while human oversight ensures safety and reliability, intervening only when necessary. Our framework seamlessly integrates human oversight, LLM agents, and heterogeneous robots to optimize task allocation and execution. Each robot is equipped with an LLM agent capable of understanding its capabilities, converting tasks into executable instructions, and reducing hallucinations through task verification and human supervision. Simulation results show that our framework outperforms state-of-the-art task planning methods, achieving higher task success rates with an improvement of 4.76%. Real-world tests demonstrate its robust zero-shot generalization feature and ability to handle diverse tasks and environments with minimal human intervention.
MARLIN: Multi-Agent Reinforcement Learning Guided by Language-Based Inter-Robot Negotiation
Oct 18, 2024Multi-agent reinforcement learning is a key method for training multi-robot systems over a series of episodes in which robots are rewarded or punished according to their performance; only once the system is trained to a suitable standard is it deployed in the real world. If the system is not trained enough, the task will likely not be completed and could pose a risk to the surrounding environment. Therefore, reaching high performance in a shorter training period can lead to significant reductions in time and resource consumption. We introduce Multi-Agent Reinforcement Learning guided by Language-based Inter-Robot Negotiation (MARLIN), which makes the training process both faster and more transparent. We equip robots with large language models that negotiate and debate the task, producing a plan that is used to guide the policy during training. We dynamically switch between using reinforcement learning and the negotiation-based approach throughout training. This offers an increase in training speed when compared to standard multi-agent reinforcement learning and allows the system to be deployed to physical hardware earlier. As robots negotiate in natural language, we can better understand the behaviour of the robots individually and as a collective. We compare the performance of our approach to multi-agent reinforcement learning and a large language model to show that our hybrid method trains faster at little cost to performance.
A Survey of Language-Based Communication in Robotics
Jun 06, 2024



Embodied robots which can interact with their environment and neighbours are increasingly being used as a test case to develop Artificial Intelligence. This creates a need for multimodal robot controllers which can operate across different types of information including text. Large Language Models are able to process and generate textual as well as audiovisual data and, more recently, robot actions. Language Models are increasingly being applied to robotic systems; these Language-Based robots leverage the power of language models in a variety of ways. Additionally, the use of language opens up multiple forms of information exchange between members of a human-robot team. This survey motivates the use of language models in robotics, and then delineates works based on the part of the overall control flow in which language is incorporated. Language can be used by human to task a robot, by a robot to inform a human, between robots as a human-like communication medium, and internally for a robot's planning and control. Applications of language-based robots are explored, and finally numerous limitations and challenges are discussed to provide a summary of the development needed for language-based robotics moving forward. Links to each paper and, if available, source code are made available in the accompanying site at https://uos-haris.online/sooratilab/papers/WillSurvey/LangRobotSurvey.php
Adaptive Human-Swarm Interaction based on Workload Measurement using Functional Near-Infrared Spectroscopy
May 13, 2024One of the challenges of human-swarm interaction (HSI) is how to manage the operator's workload. In order to do this, we propose a novel neurofeedback technique for the real-time measurement of workload using functional near-infrared spectroscopy (fNIRS). The objective is to develop a baseline for workload measurement in human-swarm interaction using fNIRS and to develop an interface that dynamically adapts to the operator's workload. The proposed method consists of using fNIRS device to measure brain activity, process this through a machine learning algorithm, and pass it on to the HSI interface. By dynamically adapting the HSI interface, the swarm operator's workload could be reduced and the performance improved.
Conversational Language Models for Human-in-the-Loop Multi-Robot Coordination
Feb 29, 2024
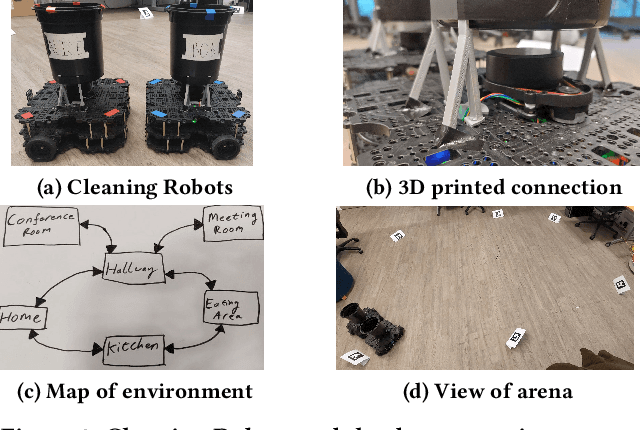
With the increasing prevalence and diversity of robots interacting in the real world, there is need for flexible, on-the-fly planning and cooperation. Large Language Models are starting to be explored in a multimodal setup for communication, coordination, and planning in robotics. Existing approaches generally use a single agent building a plan, or have multiple homogeneous agents coordinating for a simple task. We present a decentralised, dialogical approach in which a team of agents with different abilities plans solutions through peer-to-peer and human-robot discussion. We suggest that argument-style dialogues are an effective way to facilitate adaptive use of each agent's abilities within a cooperative team. Two robots discuss how to solve a cleaning problem set by a human, define roles, and agree on paths they each take. Each step can be interrupted by a human advisor and agents check their plans with the human. Agents then execute this plan in the real world, collecting rubbish from people in each room. Our implementation uses text at every step, maintaining transparency and effective human-multi-robot interaction.
The Effect of Predictive Formal Modelling at Runtime on Performance in Human-Swarm Interaction
Jan 22, 2024Formal Modelling is often used as part of the design and testing process of software development to ensure that components operate within suitable bounds even in unexpected circumstances. In this paper, we use predictive formal modelling (PFM) at runtime in a human-swarm mission and show that this integration can be used to improve the performance of human-swarm teams. We recruited 60 participants to operate a simulated aerial swarm to deliver parcels to target locations. In the PFM condition, operators were informed of the estimated completion times given the number of drones deployed, whereas in the No-PFM condition, operators did not have this information. The operators could control the mission by adding or removing drones from the mission and thereby, increasing or decreasing the overall mission cost. The evaluation of human-swarm performance relied on four key metrics: the time taken to complete tasks, the number of agents involved, the total number of tasks accomplished, and the overall cost associated with the human-swarm task. Our results show that PFM modelling at runtime improves mission performance without significantly affecting the operator's workload or the system's usability.
The Effect of Data Visualisation Quality and Task Density on Human-Swarm Interaction
Jul 17, 2023Despite the advantages of having robot swarms, human supervision is required for real-world applications. The performance of the human-swarm system depends on several factors including the data availability for the human operators. In this paper, we study the human factors aspect of the human-swarm interaction and investigate how having access to high-quality data can affect the performance of the human-swarm system - the number of tasks completed and the human trust level in operation. We designed an experiment where a human operator is tasked to operate a swarm to identify casualties in an area within a given time period. One group of operators had the option to request high-quality pictures while the other group had to base their decision on the available low-quality images. We performed a user study with 120 participants and recorded their success rate (directly logged via the simulation platform) as well as their workload and trust level (measured through a questionnaire after completing a human-swarm scenario). The findings from our study indicated that the group granted access to high-quality data exhibited an increased workload and placed greater trust in the swarm, thus confirming our initial hypothesis. However, we also found that the number of accurately identified casualties did not significantly vary between the two groups, suggesting that data quality had no impact on the successful completion of tasks.
Demonstrating Performance Benefits of Human-Swarm Teaming
Mar 23, 2023

Autonomous swarms of robots can bring robustness, scalability and adaptability to safety-critical tasks such as search and rescue but their application is still very limited. Using semi-autonomous swarms with human control can bring robot swarms to real-world applications. Human operators can define goals for the swarm, monitor their performance and interfere with, or overrule, the decisions and behaviour. We present the ``Human And Robot Interactive Swarm'' simulator (HARIS) that allows multi-user interaction with a robot swarm and facilitates qualitative and quantitative user studies through simulation of robot swarms completing tasks, from package delivery to search and rescue, with varying levels of human control. In this demonstration, we showcase the simulator by using it to study the performance gain offered by maintaining a ``human-in-the-loop'' over a fully autonomous system as an example. This is illustrated in the context of search and rescue, with an autonomous allocation of resources to those in need.