 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMADDM: Multi-Advisor Dynamic Binary Decision-Making by Maximizing the Utility
May 15, 2023Being able to infer ground truth from the responses of multiple imperfect advisors is a problem of crucial importance in many decision-making applications, such as lending, trading, investment, and crowd-sourcing. In practice, however, gathering answers from a set of advisors has a cost. Therefore, finding an advisor selection strategy that retrieves a reliable answer and maximizes the overall utility is a challenging problem. To address this problem, we propose a novel strategy for optimally selecting a set of advisers in a sequential binary decision-making setting, where multiple decisions need to be made over time. Crucially, we assume no access to ground truth and no prior knowledge about the reliability of advisers. Specifically, our approach considers how to simultaneously (1) select advisors by balancing the advisors' costs and the value of making correct decisions, (2) learn the trustworthiness of advisers dynamically without prior information by asking multiple advisers, and (3) make optimal decisions without access to the ground truth, improving this over time. We evaluate our algorithm through several numerical experiments. The results show that our approach outperforms two other methods that combine state-of-the-art models.
Multi-trainer Interactive Reinforcement Learning System
Oct 14, 2022


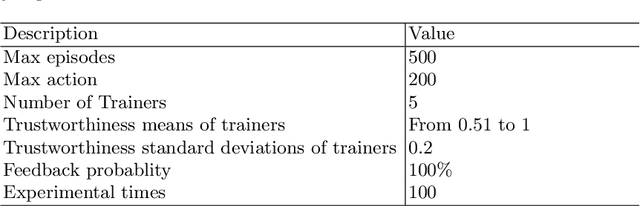
Interactive reinforcement learning can effectively facilitate the agent training via human feedback. However, such methods often require the human teacher to know what is the correct action that the agent should take. In other words, if the human teacher is not always reliable, then it will not be consistently able to guide the agent through its training. In this paper, we propose a more effective interactive reinforcement learning system by introducing multiple trainers, namely Multi-Trainer Interactive Reinforcement Learning (MTIRL), which could aggregate the binary feedback from multiple non-perfect trainers into a more reliable reward for an agent training in a reward-sparse environment. In particular, our trainer feedback aggregation experiments show that our aggregation method has the best accuracy when compared with the majority voting, the weighted voting, and the Bayesian method. Finally, we conduct a grid-world experiment to show that the policy trained by the MTIRL with the review model is closer to the optimal policy than that without a review model.
From Intelligent Agents to Trustworthy Human-Centred Multiagent Systems
Oct 05, 2022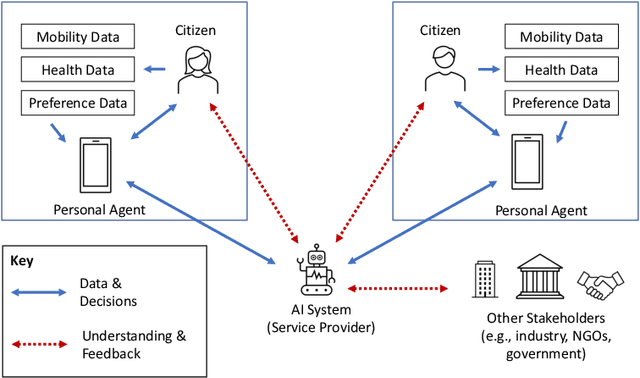
The Agents, Interaction and Complexity research group at the University of Southampton has a long track record of research in multiagent systems (MAS). We have made substantial scientific contributions across learning in MAS, game-theoretic techniques for coordinating agent systems, and formal methods for representation and reasoning. We highlight key results achieved by the group and elaborate on recent work and open research challenges in developing trustworthy autonomous systems and deploying human-centred AI systems that aim to support societal good.
* Appears in the Special Issue on Multi-Agent Systems Research in the United Kingdom