 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNavigating Taxonomic Expansions of Entity Sets Driven by Knowledge Bases
Dec 17, 2025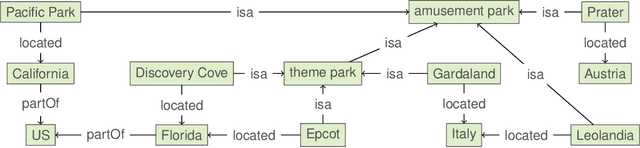

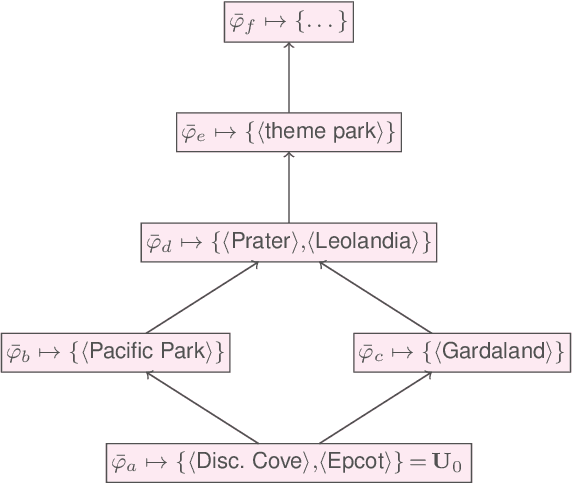

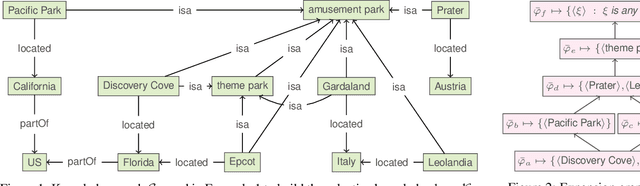
Recognizing similarities among entities is central to both human cognition and computational intelligence. Within this broader landscape, Entity Set Expansion is one prominent task aimed at taking an initial set of (tuples of) entities and identifying additional ones that share relevant semantic properties with the former -- potentially repeating the process to form increasingly broader sets. However, this ``linear'' approach does not unveil the richer ``taxonomic'' structures present in knowledge resources. A recent logic-based framework introduces the notion of an expansion graph: a rooted directed acyclic graph where each node represents a semantic generalization labeled by a logical formula, and edges encode strict semantic inclusion. This structure supports taxonomic expansions of entity sets driven by knowledge bases. Yet, the potentially large size of such graphs may make full materialization impractical in real-world scenarios. To overcome this, we formalize reasoning tasks that check whether two tuples belong to comparable, incomparable, or the same nodes in the graph. Our results show that, under realistic assumptions -- such as bounding the input or limiting entity descriptions -- these tasks can be implemented efficiently. This enables local, incremental navigation of expansion graphs, supporting practical applications without requiring full graph construction.
Characterizing Nexus of Similarity within Knowledge Bases: A Logic-based Framework and its Computational Complexity Aspects
Mar 19, 2023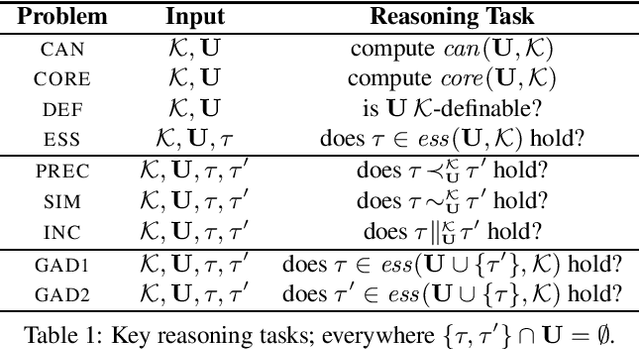
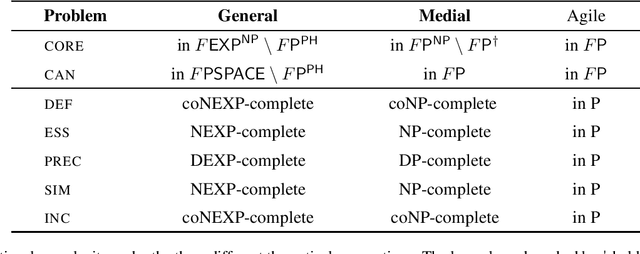

Similarities between entities occur frequently in many real-world scenarios. For over a century, researchers in different fields have proposed a range of approaches to measure the similarity between entities. More recently, inspired by "Google Sets", significant academic and commercial efforts have been devoted to expanding a given set of entities with similar ones. As a result, existing approaches nowadays are able to take into account properties shared by entities, hereinafter called nexus of similarity. Accordingly, machines are largely able to deal with both similarity measures and set expansions. To the best of our knowledge, however, there is no way to characterize nexus of similarity between entities, namely identifying such nexus in a formal and comprehensive way so that they are both machine- and human-readable; moreover, there is a lack of consensus on evaluating existing approaches for weakly similar entities. As a first step towards filling these gaps, we aim to complement existing literature by developing a novel logic-based framework to formally and automatically characterize nexus of similarity between tuples of entities within a knowledge base. Furthermore, we analyze computational complexity aspects of this framework.