 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPT Assisted Annotation of Rhetorical and Linguistic Features for Interpretable Propaganda Technique Detection in News Text
Jul 16, 2024
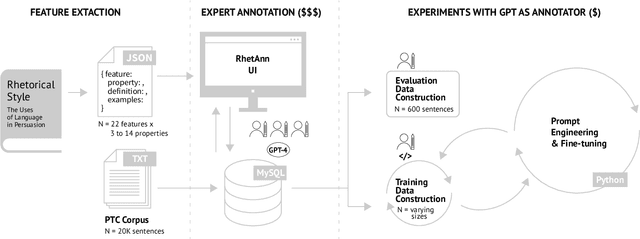


While the use of machine learning for the detection of propaganda techniques in text has garnered considerable attention, most approaches focus on "black-box" solutions with opaque inner workings. Interpretable approaches provide a solution, however, they depend on careful feature engineering and costly expert annotated data. Additionally, language features specific to propagandistic text are generally the focus of rhetoricians or linguists, and there is no data set labeled with such features suitable for machine learning. This study codifies 22 rhetorical and linguistic features identified in literature related to the language of persuasion for the purpose of annotating an existing data set labeled with propaganda techniques. To help human experts annotate natural language sentences with these features, RhetAnn, a web application, was specifically designed to minimize an otherwise considerable mental effort. Finally, a small set of annotated data was used to fine-tune GPT-3.5, a generative large language model (LLM), to annotate the remaining data while optimizing for financial cost and classification accuracy. This study demonstrates how combining a small number of human annotated examples with GPT can be an effective strategy for scaling the annotation process at a fraction of the cost of traditional annotation relying solely on human experts. The results are on par with the best performing model at the time of writing, namely GPT-4, at 10x less the cost. Our contribution is a set of features, their properties, definitions, and examples in a machine-readable format, along with the code for RhetAnn and the GPT prompts and fine-tuning procedures for advancing state-of-the-art interpretable propaganda technique detection.