 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuro-symbolic AI for Predictive Maintenance (PdM) -- review and recommendations
Jan 31, 2026In this document we perform a systematic review the State-of-the-art in Predictive Maintenance (PdM) over the last five years in industrial settings such as commercial buildings, pharmaceutical facilities, or semi-conductor manufacturing. In general, data-driven methods such as those based on deep learning, exhibit higher accuracy than traditional knowledge-based systems. These systems however, are not without significant limitations. The need for large labeled data sets, a lack of generalizibility to new environments (out-of-distribution generalization), and a lack of transparency at inference time are some of the obstacles to adoption in real world environments. In contrast, traditional approaches based on domain expertise in the form of rules, logic or first principles suffer from poor accuracy, many false positives and a need for ongoing expert supervision and manual tuning. While the majority of approaches in recent literature utilize some form of data-driven architecture, there are hybrid systems which also take into account domain specific knowledge. Such hybrid systems have the potential to overcome the weaknesses of either approach on its own while preserving their strengths. We propose taking the hybrid approach even further and integrating deep learning with symbolic logic, or Neuro-symbolic AI, to create more accurate, explainable, interpretable, and robust systems. We describe several neuro-symbolic architectures and examine their strengths and limitations within the PdM domain. We focus specifically on methods which involve the use of sensor data and manually crafted rules as inputs by describing concrete NeSy architectures. In short, this survey outlines the context of modern maintenance, defines key concepts, establishes a generalized framework, reviews current modeling approaches and challenges, and introduces the proposed focus on Neuro-symbolic AI (NESY).
GPT Assisted Annotation of Rhetorical and Linguistic Features for Interpretable Propaganda Technique Detection in News Text
Jul 16, 2024
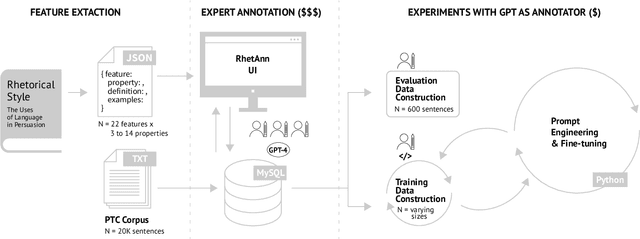


While the use of machine learning for the detection of propaganda techniques in text has garnered considerable attention, most approaches focus on "black-box" solutions with opaque inner workings. Interpretable approaches provide a solution, however, they depend on careful feature engineering and costly expert annotated data. Additionally, language features specific to propagandistic text are generally the focus of rhetoricians or linguists, and there is no data set labeled with such features suitable for machine learning. This study codifies 22 rhetorical and linguistic features identified in literature related to the language of persuasion for the purpose of annotating an existing data set labeled with propaganda techniques. To help human experts annotate natural language sentences with these features, RhetAnn, a web application, was specifically designed to minimize an otherwise considerable mental effort. Finally, a small set of annotated data was used to fine-tune GPT-3.5, a generative large language model (LLM), to annotate the remaining data while optimizing for financial cost and classification accuracy. This study demonstrates how combining a small number of human annotated examples with GPT can be an effective strategy for scaling the annotation process at a fraction of the cost of traditional annotation relying solely on human experts. The results are on par with the best performing model at the time of writing, namely GPT-4, at 10x less the cost. Our contribution is a set of features, their properties, definitions, and examples in a machine-readable format, along with the code for RhetAnn and the GPT prompts and fine-tuning procedures for advancing state-of-the-art interpretable propaganda technique detection.
Is Neuro-Symbolic AI Meeting its Promise in Natural Language Processing? A Structured Review
Feb 24, 2022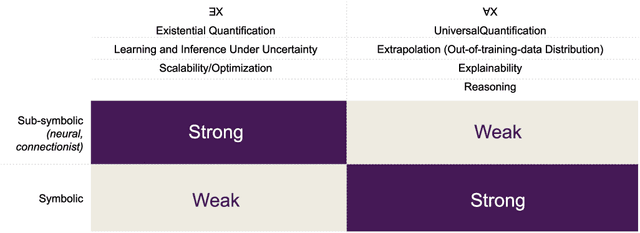
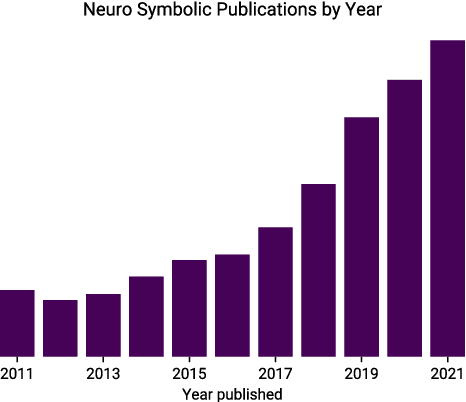

Advocates for Neuro-Symbolic AI (NeSy) assert that combining deep learning with symbolic reasoning will lead to stronger AI than either paradigm on its own. As successful as deep learning has been, it is generally accepted that even our best deep learning systems are not very good at abstract reasoning. And since reasoning is inextricably linked to language, it makes intuitive sense that Natural Language Processing (NLP), would be a particularly well-suited candidate for NeSy. We conduct a structured review of studies implementing NeSy for NLP, challenges and future directions, and aim to answer the question of whether NeSy is indeed meeting its promises: reasoning, out-of-distribution generalization, interpretability, learning and reasoning from small data, and transferability to new domains. We examine the impact of knowledge representation, such as rules and semantic networks, language structure and relational structure, and whether implicit or explicit reasoning contributes to higher promise scores. We find that knowledge encoded in relational structures and explicit reasoning tend to lead to more NeSy goals being satisfied. We also advocate for a more methodical approach to the application of theories of reasoning, which we hope can reduce some of the friction between the symbolic and sub-symbolic schools of AI.