 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybridProver: Augmenting Theorem Proving with LLM-Driven Proof Synthesis and Refinement
May 21, 2025Formal methods is pivotal for verifying the reliability of critical systems through rigorous mathematical proofs. However, its adoption is hindered by labor-intensive manual proofs and the expertise required to use theorem provers. Recent advancements in large language models (LLMs) offer new opportunities for automated theorem proving. Two promising approaches are generating tactics step by step and generating a whole proof directly with an LLM. However, existing work makes no attempt to combine the two approaches. In this work, we introduce HybridProver, a dual-model proof synthesis framework that combines tactic-based generation and whole-proof synthesis to harness the benefits of both approaches. HybridProver generates whole proof candidates for evaluation directly, then extracts proof sketches from those candidates. It then uses a tactic-based generation model that integrates automated tools to complete the sketches via stepwise refinement. We implement HybridProver for the Isabelle theorem prover and fine-tune LLMs on our optimized Isabelle datasets. Evaluation on the miniF2F dataset illustrates HybridProver's effectiveness. We achieve a 59.4% success rate on miniF2F, where the previous SOTA is 56.1%. Our ablation studies show that this SOTA result is attributable to combining whole-proof and tactic-based generation. Additionally, we show how the dataset quality, training parameters, and sampling diversity affect the final result during automated theorem proving with LLMs. All of our code, datasets, and LLMs are open source.
Psychometric-Based Evaluation for Theorem Proving with Large Language Models
Feb 02, 2025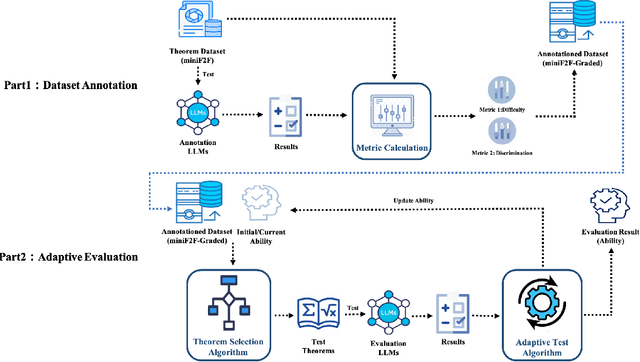

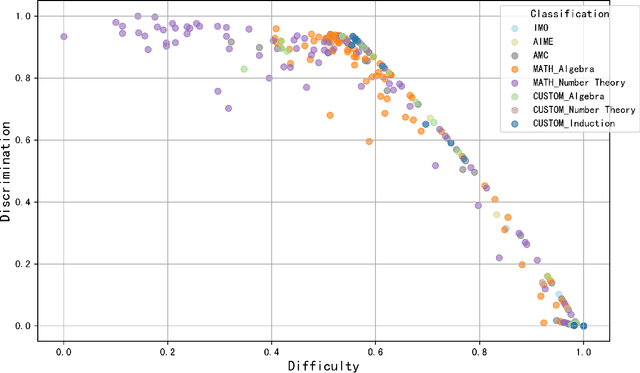

Large language models (LLMs) for formal theorem proving have become a prominent research focus. At present, the proving ability of these LLMs is mainly evaluated through proof pass rates on datasets such as miniF2F. However, this evaluation method overlooks the varying importance of theorems. As a result, it fails to highlight the real performance disparities between LLMs and leads to high evaluation costs. This study proposes a psychometric-based evaluation method for theorem proving with LLMs, comprising two main components: Dataset Annotation and Adaptive Evaluation. First, we propose a metric calculation method to annotate the dataset with difficulty and discrimination metrics. Specifically, we annotate each theorem in the miniF2F dataset and grade them into varying difficulty levels according to the performance of LLMs, resulting in an enhanced dataset: miniF2F-Graded. Experimental results show that the difficulty grading in miniF2F-Graded better reflects the theorem difficulty perceived by LLMs. Secondly, we design an adaptive evaluation method to dynamically select the most suitable theorems for testing based on the annotated metrics and the real-time performance of LLMs. We apply this method to evaluate 10 LLMs. The results show that our method finely highlights the performance disparities between LLMs. It also reduces evaluation costs by using only 23% of the theorems in the dataset.