 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLength-Induced Embedding Collapse in Transformer-based Models
Paper and Code
Oct 31, 2024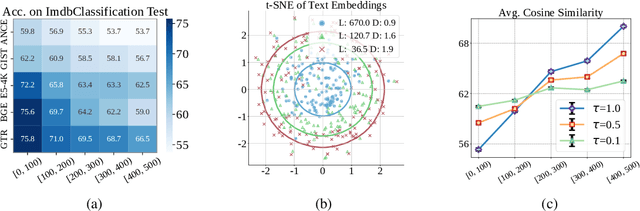
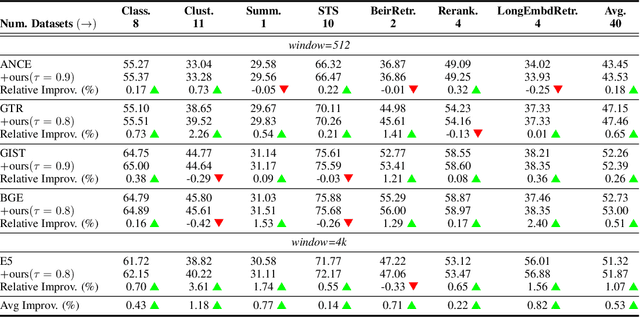
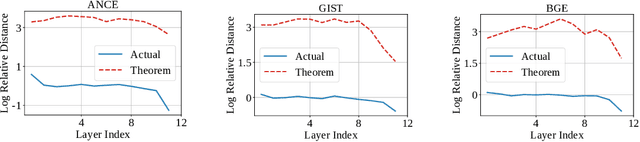

Text embeddings enable various applications, but their performance deteriorates on longer texts. In this paper, we find that the performance degradation is due to a phenomenon called Length Collapse, where longer text embeddings collapse into a narrow space. This collapse results in a distributional inconsistency between embeddings of different text lengths, ultimately hurting the performance of downstream tasks. Theoretically, by considering the self-attention mechanism inherently functions as a low-pass filter, we prove that long sequences increase the attenuation rate of the low-pass filter effect of the self-attention mechanism. With layers going deeper, excessive low-pass filtering causes the token signals to retain only their Direct-Current (DC) component, which means the input token feature maps will collapse into a narrow space, especially in long texts. Based on the above analysis, we propose to mitigate the undesirable length collapse limitation by introducing a temperature in softmax(), which achieves a higher low-filter attenuation rate. The tuning-free method, called TempScale, can be plugged into multiple transformer-based embedding models. Empirically, we demonstrate that TempScale can improve existing embedding models, especially on long text inputs, bringing up to 0.53% performance gains on 40 datasets from Massive Text Embedding Benchmark (MTEB) and 0.82% performance gains on 4 datasets from LongEmbed, which specifically focuses on long context retrieval.