 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking of the Image Salient Object Detection: Object-level Semantic Saliency Re-ranking First, Pixel-wise Saliency Refinement Latter
Paper and Code

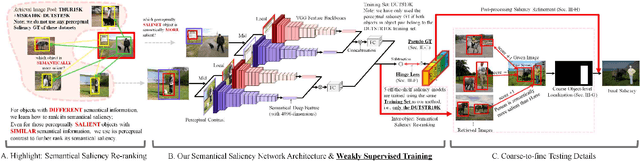


The real human attention is an interactive activity between our visual system and our brain, using both low-level visual stimulus and high-level semantic information. Previous image salient object detection (SOD) works conduct their saliency predictions in a multi-task manner, i.e., performing pixel-wise saliency regression and segmentation-like saliency refinement at the same time, which degenerates their feature backbones in revealing semantic information. However, given an image, we tend to pay more attention to those regions which are semantically salient even in the case that these regions are perceptually not the most salient ones at first glance. In this paper, we divide the SOD problem into two sequential tasks: 1) we propose a lightweight, weakly supervised deep network to coarsely locate those semantically salient regions first; 2) then, as a post-processing procedure, we selectively fuse multiple off-the-shelf deep models on these semantically salient regions as the pixel-wise saliency refinement. In sharp contrast to the state-of-the-art (SOTA) methods that focus on learning pixel-wise saliency in "single image" using perceptual clues mainly, our method has investigated the "object-level semantic ranks between multiple images", of which the methodology is more consistent with the real human attention mechanism. Our method is simple yet effective, which is the first attempt to consider the salient object detection mainly as an object-level semantic re-ranking problem.