 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWinDB: HMD-free and Distortion-free Panoptic Video Fixation Learning
May 23, 2023To date, the widely-adopted way to perform fixation collection in panoptic video is based on a head-mounted display (HMD), where participants' fixations are collected while wearing an HMD to explore the given panoptic scene freely. However, this widely-used data collection method is insufficient for training deep models to accurately predict which regions in a given panoptic are most important when it contains intermittent salient events. The main reason is that there always exist "blind zooms" when using HMD to collect fixations since the participants cannot keep spinning their heads to explore the entire panoptic scene all the time. Consequently, the collected fixations tend to be trapped in some local views, leaving the remaining areas to be the "blind zooms". Therefore, fixation data collected using HMD-based methods that accumulate local views cannot accurately represent the overall global importance of complex panoramic scenes. This paper introduces the auxiliary Window with a Dynamic Blurring (WinDB) fixation collection approach for panoptic video, which doesn't need HMD and is blind-zoom-free. Thus, the collected fixations can well reflect the regional-wise importance degree. Using our WinDB approach, we have released a new PanopticVideo-300 dataset, containing 300 panoptic clips covering over 225 categories. Besides, we have presented a simple baseline design to take full advantage of PanopticVideo-300 to handle the blind-zoom-free attribute-induced fixation shifting problem. Our WinDB approach, PanopticVideo-300, and tailored fixation prediction model are all publicly available at https://github.com/360submit/WinDB.
Weakly Supervised Visual-Auditory Saliency Detection with Multigranularity Perception
Jan 01, 2022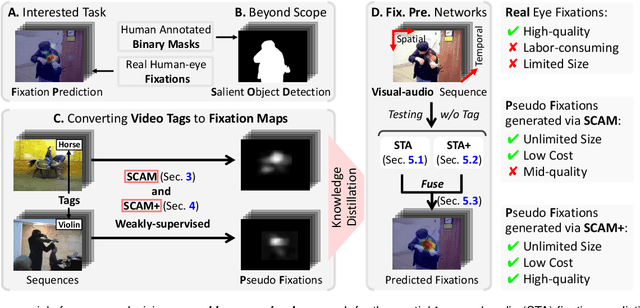
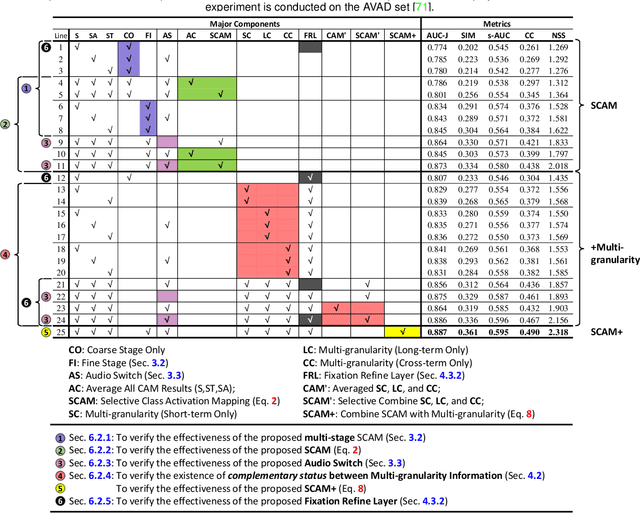
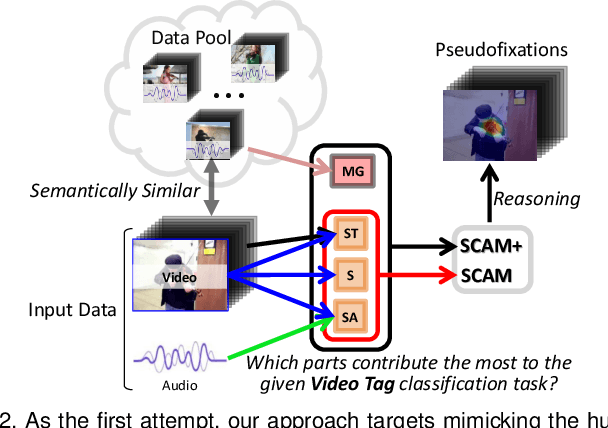
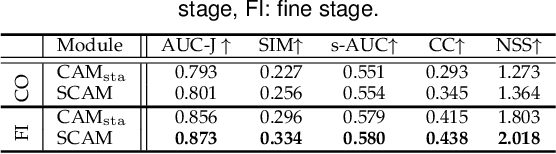
Thanks to the rapid advances in deep learning techniques and the wide availability of large-scale training sets, the performance of video saliency detection models has been improving steadily and significantly. However, deep learning-based visualaudio fixation prediction is still in its infancy. At present, only a few visual-audio sequences have been furnished, with real fixations being recorded in real visual-audio environments. Hence, it would be neither efficient nor necessary to recollect real fixations under the same visual-audio circumstances. To address this problem, this paper promotes a novel approach in a weakly supervised manner to alleviate the demand of large-scale training sets for visual-audio model training. By using only the video category tags, we propose the selective class activation mapping (SCAM) and its upgrade (SCAM+). In the spatial-temporal-audio circumstance, the former follows a coarse-to-fine strategy to select the most discriminative regions, and these regions are usually capable of exhibiting high consistency with the real human-eye fixations. The latter equips the SCAM with an additional multi-granularity perception mechanism, making the whole process more consistent with that of the real human visual system. Moreover, we distill knowledge from these regions to obtain complete new spatial-temporal-audio (STA) fixation prediction (FP) networks, enabling broad applications in cases where video tags are not available. Without resorting to any real human-eye fixation, the performances of these STA FP networks are comparable to those of fully supervised networks. The code and results are publicly available at https://github.com/guotaowang/STANet.
Exploring Rich and Efficient Spatial Temporal Interactions for Real Time Video Salient Object Detection
Aug 07, 2020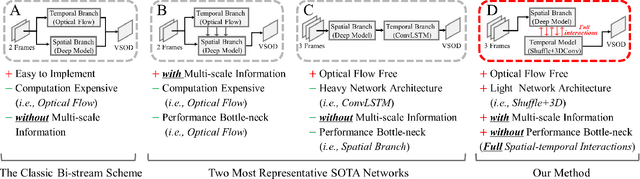
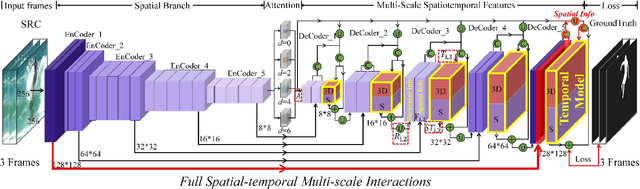
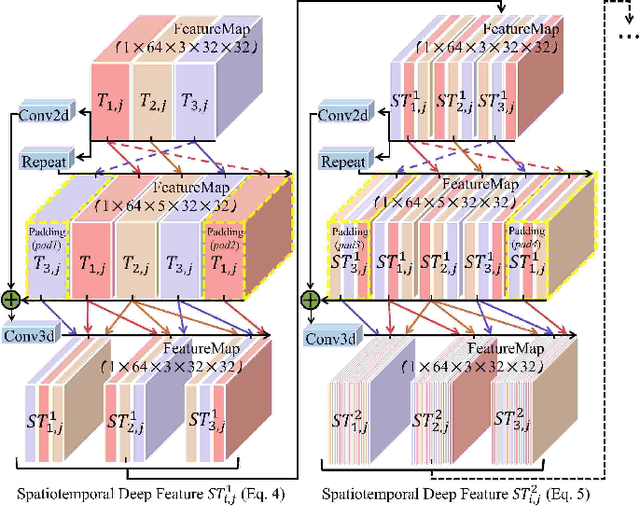
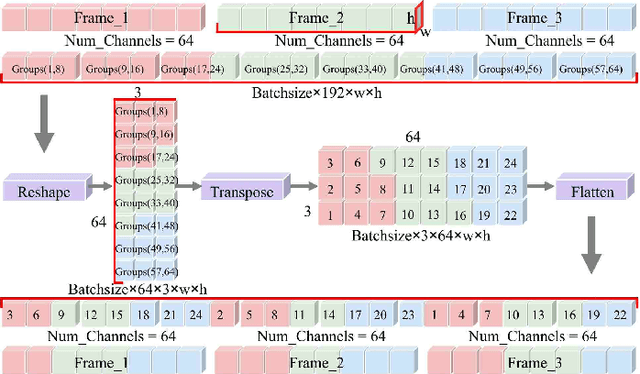
The current main stream methods formulate their video saliency mainly from two independent venues, i.e., the spatial and temporal branches. As a complementary component, the main task for the temporal branch is to intermittently focus the spatial branch on those regions with salient movements. In this way, even though the overall video saliency quality is heavily dependent on its spatial branch, however, the performance of the temporal branch still matter. Thus, the key factor to improve the overall video saliency is how to further boost the performance of these branches efficiently. In this paper, we propose a novel spatiotemporal network to achieve such improvement in a full interactive fashion. We integrate a lightweight temporal model into the spatial branch to coarsely locate those spatially salient regions which are correlated with trustworthy salient movements. Meanwhile, the spatial branch itself is able to recurrently refine the temporal model in a multi-scale manner. In this way, both the spatial and temporal branches are able to interact with each other, achieving the mutual performance improvement. Our method is easy to implement yet effective, achieving high quality video saliency detection in real-time speed with 50 FPS.