 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot All Tokens Are Equal: Human-centric Visual Analysis via Token Clustering Transformer
Paper and Code



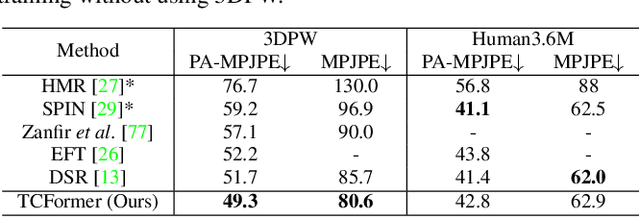
Vision transformers have achieved great successes in many computer vision tasks. Most methods generate vision tokens by splitting an image into a regular and fixed grid and treating each cell as a token. However, not all regions are equally important in human-centric vision tasks, e.g., the human body needs a fine representation with many tokens, while the image background can be modeled by a few tokens. To address this problem, we propose a novel Vision Transformer, called Token Clustering Transformer (TCFormer), which merges tokens by progressive clustering, where the tokens can be merged from different locations with flexible shapes and sizes. The tokens in TCFormer can not only focus on important areas but also adjust the token shapes to fit the semantic concept and adopt a fine resolution for regions containing critical details, which is beneficial to capturing detailed information. Extensive experiments show that TCFormer consistently outperforms its counterparts on different challenging human-centric tasks and datasets, including whole-body pose estimation on COCO-WholeBody and 3D human mesh reconstruction on 3DPW. Code is available at https://github.com/zengwang430521/TCFormer.git