 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOWA: Multiple-in-One Image Warping Model
Paper and Code


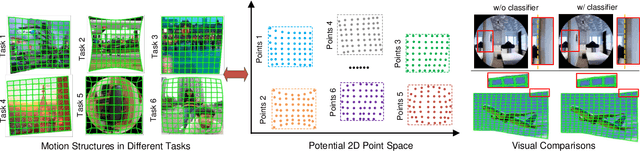

While recent image warping approaches achieved remarkable success on existing benchmarks, they still require training separate models for each specific task and cannot generalize well to different camera models or customized manipulations. To address diverse types of warping in practice, we propose a Multiple-in-One image WArping model (named MOWA) in this work. Specifically, we mitigate the difficulty of multi-task learning by disentangling the motion estimation at both the region level and pixel level. To further enable dynamic task-aware image warping, we introduce a lightweight point-based classifier that predicts the task type, serving as prompts to modulate the feature maps for better estimation. To our knowledge, this is the first work that solves multiple practical warping tasks in one single model. Extensive experiments demonstrate that our MOWA, which is trained on six tasks for multiple-in-one image warping, outperforms state-of-the-art task-specific models across most tasks. Moreover, MOWA also exhibits promising potential to generalize into unseen scenes, as evidenced by cross-domain and zero-shot evaluations. The code will be made publicly available.