 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGDSG: Graph Diffusion-based Solution Generator for Optimization Problems in MEC Networks
Dec 15, 2024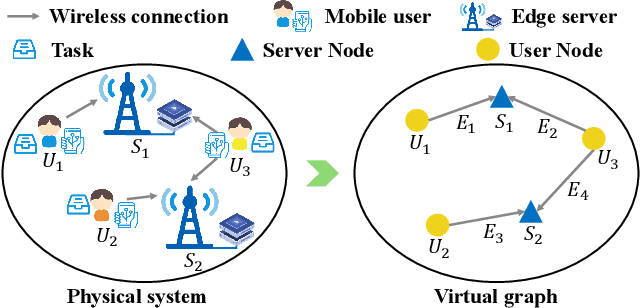
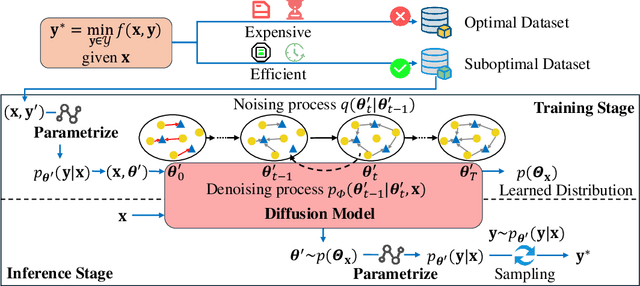
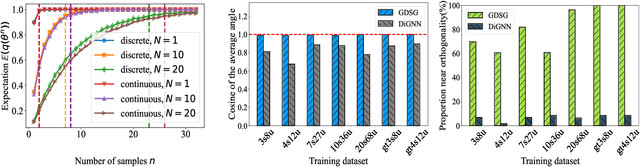
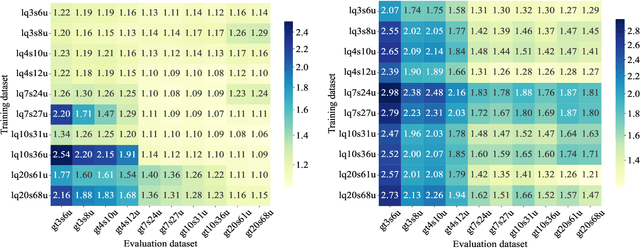
Optimization is crucial for MEC networks to function efficiently and reliably, most of which are NP-hard and lack efficient approximation algorithms. This leads to a paucity of optimal solution, constraining the effectiveness of conventional deep learning approaches. Most existing learning-based methods necessitate extensive optimal data and fail to exploit the potential benefits of suboptimal data that can be obtained with greater efficiency and effectiveness. Taking the multi-server multi-user computation offloading (MSCO) problem, which is widely observed in systems like Internet-of-Vehicles (IoV) and Unmanned Aerial Vehicle (UAV) networks, as a concrete scenario, we present a Graph Diffusion-based Solution Generation (GDSG) method. This approach is designed to work with suboptimal datasets while converging to the optimal solution large probably. We transform the optimization issue into distribution-learning and offer a clear explanation of learning from suboptimal training datasets. We build GDSG as a multi-task diffusion model utilizing a Graph Neural Network (GNN) to acquire the distribution of high-quality solutions. We use a simple and efficient heuristic approach to obtain a sufficient amount of training data composed entirely of suboptimal solutions. In our implementation, we enhance the backbone GNN and achieve improved generalization. GDSG also reaches nearly 100\% task orthogonality, ensuring no interference between the discrete and continuous generation tasks. We further reveal that this orthogonality arises from the diffusion-related training loss, rather than the neural network architecture itself. The experiments demonstrate that GDSG surpasses other benchmark methods on both the optimal and suboptimal training datasets. The MSCO datasets has open-sourced at http://ieee-dataport.org/13824, as well as the GDSG algorithm codes at https://github.com/qiyu3816/GDSG.
GDSG: Graph Diffusion-based Solution Generation for Optimization Problems in MEC Networks
Dec 11, 2024Optimization is crucial for MEC networks to function efficiently and reliably, most of which are NP-hard and lack efficient approximation algorithms. This leads to a paucity of optimal solution, constraining the effectiveness of conventional deep learning approaches. Most existing learning-based methods necessitate extensive optimal data and fail to exploit the potential benefits of suboptimal data that can be obtained with greater efficiency and effectiveness. Taking the multi-server multi-user computation offloading (MSCO) problem, which is widely observed in systems like Internet-of-Vehicles (IoV) and Unmanned Aerial Vehicle (UAV) networks, as a concrete scenario, we present a Graph Diffusion-based Solution Generation (GDSG) method. This approach is designed to work with suboptimal datasets while converging to the optimal solution large probably. We transform the optimization issue into distribution-learning and offer a clear explanation of learning from suboptimal training datasets. We build GDSG as a multi-task diffusion model utilizing a Graph Neural Network (GNN) to acquire the distribution of high-quality solutions. We use a simple and efficient heuristic approach to obtain a sufficient amount of training data composed entirely of suboptimal solutions. In our implementation, we enhance the backbone GNN and achieve improved generalization. GDSG also reaches nearly 100\% task orthogonality, ensuring no interference between the discrete and continuous generation tasks. We further reveal that this orthogonality arises from the diffusion-related training loss, rather than the neural network architecture itself. The experiments demonstrate that GDSG surpasses other benchmark methods on both the optimal and suboptimal training datasets. The MSCO datasets has open-sourced at http://ieee-dataport.org/13824, as well as the GDSG algorithm codes at https://github.com/qiyu3816/GDSG.
Diffusion Models as Network Optimizers: Explorations and Analysis
Nov 04, 2024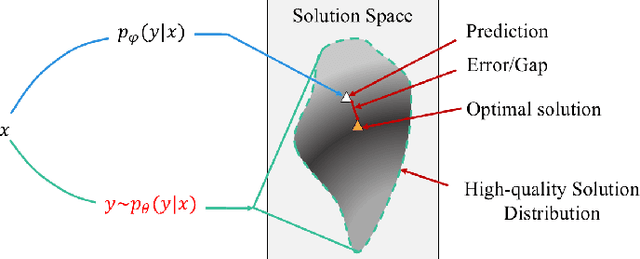
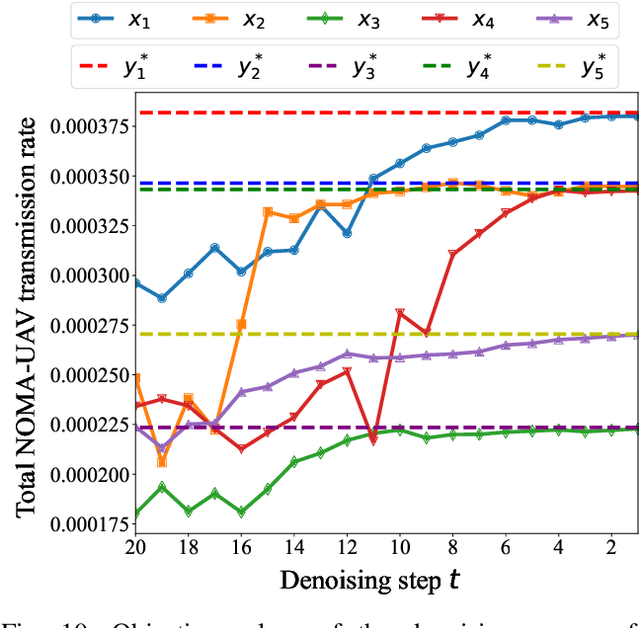
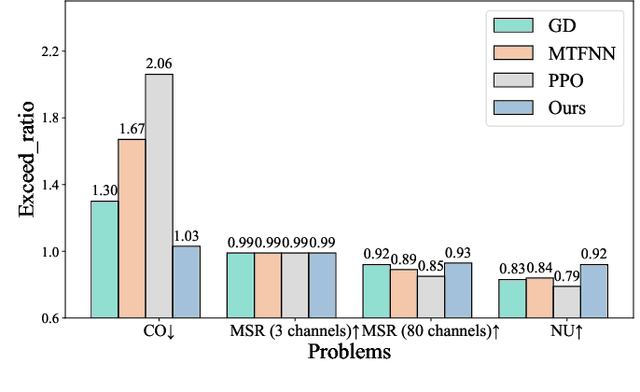
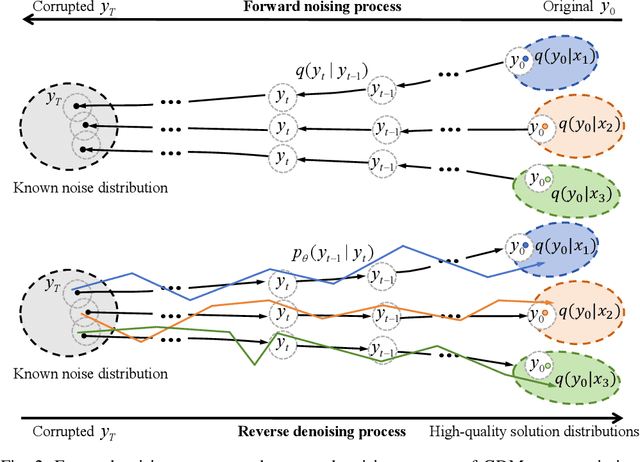
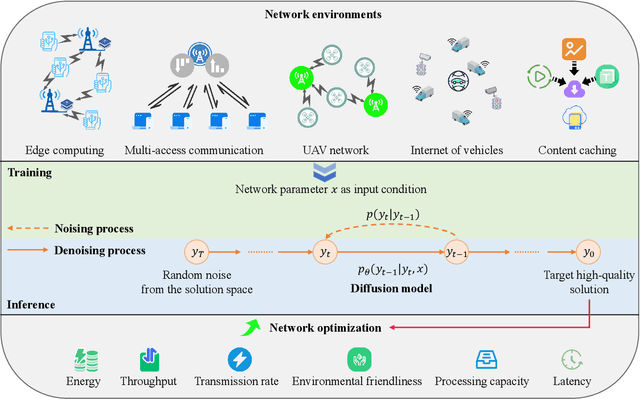
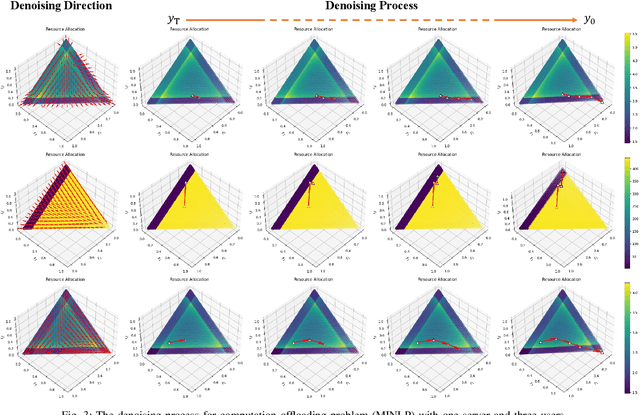
Network optimization is a fundamental challenge in the Internet of Things (IoT) network, often characterized by complex features that make it difficult to solve these problems. Recently, generative diffusion models (GDMs) have emerged as a promising new approach to network optimization, with the potential to directly address these optimization problems. However, the application of GDMs in this field is still in its early stages, and there is a noticeable lack of theoretical research and empirical findings. In this study, we first explore the intrinsic characteristics of generative models. Next, we provide a concise theoretical proof and intuitive demonstration of the advantages of generative models over discriminative models in network optimization. Based on this exploration, we implement GDMs as optimizers aimed at learning high-quality solution distributions for given inputs, sampling from these distributions during inference to approximate or achieve optimal solutions. Specifically, we utilize denoising diffusion probabilistic models (DDPMs) and employ a classifier-free guidance mechanism to manage conditional guidance based on input parameters. We conduct extensive experiments across three challenging network optimization problems. By investigating various model configurations and the principles of GDMs as optimizers, we demonstrate the ability to overcome prediction errors and validate the convergence of generated solutions to optimal solutions.We provide code and data at https://github.com/qiyu3816/DiffSG.
DiffSG: A Generative Solver for Network Optimization with Diffusion Model
Aug 13, 2024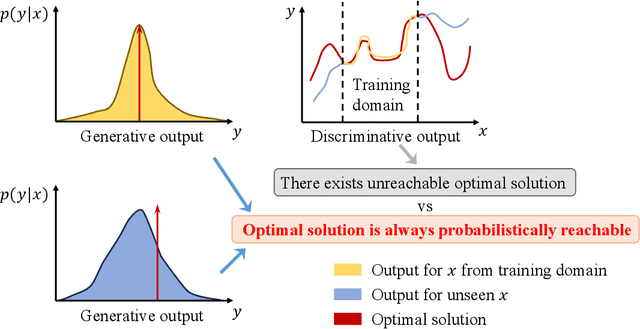

Diffusion generative models, famous for their performance in image generation, are popular in various cross-domain applications. However, their use in the communication community has been mostly limited to auxiliary tasks like data modeling and feature extraction. These models hold greater promise for fundamental problems in network optimization compared to traditional machine learning methods. Discriminative deep learning often falls short due to its single-step input-output mapping and lack of global awareness of the solution space, especially given the complexity of network optimization's objective functions. In contrast, diffusion generative models can consider a broader range of solutions and exhibit stronger generalization by learning parameters that describe the distribution of the underlying solution space, with higher probabilities assigned to better solutions. We propose a new framework Diffusion Model-based Solution Generation (DiffSG), which leverages the intrinsic distribution learning capabilities of diffusion generative models to learn high-quality solution distributions based on given inputs. The optimal solution within this distribution is highly probable, allowing it to be effectively reached through repeated sampling. We validate the performance of DiffSG on several typical network optimization problems, including mixed-integer non-linear programming, convex optimization, and hierarchical non-convex optimization. Our results show that DiffSG outperforms existing baselines. In summary, we demonstrate the potential of diffusion generative models in tackling complex network optimization problems and outline a promising path for their broader application in the communication community.
A Multi-Head Ensemble Multi-Task Learning Approach for Dynamical Computation Offloading
Sep 02, 2023
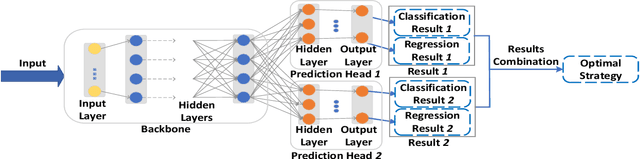
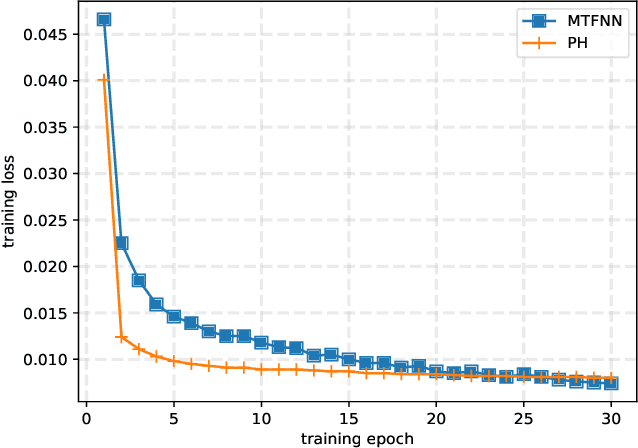

Computation offloading has become a popular solution to support computationally intensive and latency-sensitive applications by transferring computing tasks to mobile edge servers (MESs) for execution, which is known as mobile/multi-access edge computing (MEC). To improve the MEC performance, it is required to design an optimal offloading strategy that includes offloading decision (i.e., whether offloading or not) and computational resource allocation of MEC. The design can be formulated as a mixed-integer nonlinear programming (MINLP) problem, which is generally NP-hard and its effective solution can be obtained by performing online inference through a well-trained deep neural network (DNN) model. However, when the system environments change dynamically, the DNN model may lose efficacy due to the drift of input parameters, thereby decreasing the generalization ability of the DNN model. To address this unique challenge, in this paper, we propose a multi-head ensemble multi-task learning (MEMTL) approach with a shared backbone and multiple prediction heads (PHs). Specifically, the shared backbone will be invariant during the PHs training and the inferred results will be ensembled, thereby significantly reducing the required training overhead and improving the inference performance. As a result, the joint optimization problem for offloading decision and resource allocation can be efficiently solved even in a time-varying wireless environment. Experimental results show that the proposed MEMTL outperforms benchmark methods in both the inference accuracy and mean square error without requiring additional training data.