 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Deep Learning Pipelines for Accurate Cost Estimations Over Large Scale Query Workload
Paper and Code
Mar 23, 2021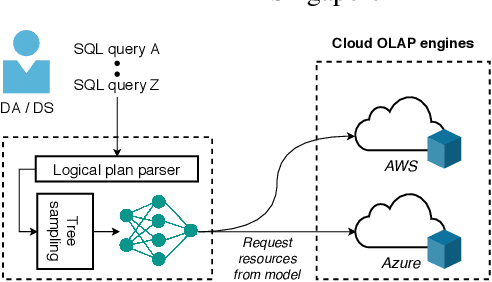
The use of deep learning models for forecasting the resource consumption patterns of SQL queries have recently been a popular area of study. With many companies using cloud platforms to power their data lakes for large scale analytic demands, these models form a critical part of the pipeline in managing cloud resource provisioning. While these models have demonstrated promising accuracy, training them over large scale industry workloads are expensive. Space inefficiencies of encoding techniques over large numbers of queries and excessive padding used to enforce shape consistency across diverse query plans implies 1) longer model training time and 2) the need for expensive, scaled up infrastructure to support batched training. In turn, we developed Prestroid, a tree convolution based data science pipeline that accurately predicts resource consumption patterns of query traces, but at a much lower cost. We evaluated our pipeline over 19K Presto OLAP queries from Grab, on a data lake of more than 20PB of data. Experimental results imply that our pipeline outperforms benchmarks on predictive accuracy, contributing to more precise resource prediction for large-scale workloads, yet also reduces per-batch memory footprint by 13.5x and per-epoch training time by 3.45x. We demonstrate direct cost savings of up to 13.2x for large batched model training over Microsoft Azure VMs.