 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf Adaptive Threshold Pseudo-labeling and Unreliable Sample Contrastive Loss for Semi-supervised Image Classification
Paper and Code
Jul 04, 2024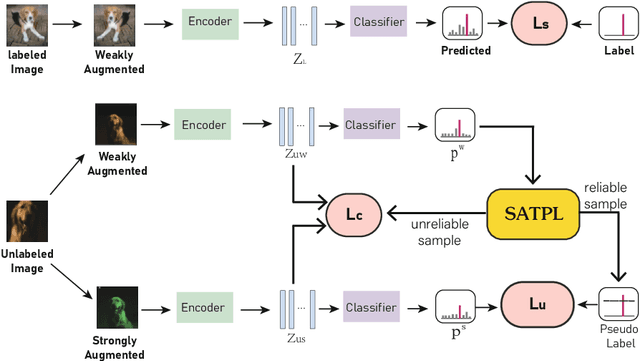



Semi-supervised learning is attracting blooming attention, due to its success in combining unlabeled data. However, pseudo-labeling-based semi-supervised approaches suffer from two problems in image classification: (1) Existing methods might fail to adopt suitable thresholds since they either use a pre-defined/fixed threshold or an ad-hoc threshold adjusting scheme, resulting in inferior performance and slow convergence. (2) Discarding unlabeled data with confidence below the thresholds results in the loss of discriminating information. To solve these issues, we develop an effective method to make sufficient use of unlabeled data. Specifically, we design a self adaptive threshold pseudo-labeling strategy, which thresholds for each class can be dynamically adjusted to increase the number of reliable samples. Meanwhile, in order to effectively utilise unlabeled data with confidence below the thresholds, we propose an unreliable sample contrastive loss to mine the discriminative information in low-confidence samples by learning the similarities and differences between sample features. We evaluate our method on several classification benchmarks under partially labeled settings and demonstrate its superiority over the other approaches.