 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCineSRD: Leveraging Visual, Acoustic, and Linguistic Cues for Open-World Visual Media Speaker Diarization
Mar 17, 2026Traditional speaker diarization systems have primarily focused on constrained scenarios such as meetings and interviews, where the number of speakers is limited and acoustic conditions are relatively clean. To explore open-world speaker diarization, we extend this task to the visual media domain, encompassing complex audiovisual programs such as films and TV series. This new setting introduces several challenges, including long-form video understanding, a large number of speakers, cross-modal asynchrony between audio and visual cues, and uncontrolled in-the-wild variability. To address these challenges, we propose Cinematic Speaker Registration & Diarization (CineSRD), a unified multimodal framework that leverages visual, acoustic, and linguistic cues from video, speech, and subtitles for speaker annotation. CineSRD first performs visual anchor clustering to register initial speakers and then integrates an audio language model for speaker turn detection, refining annotations and supplementing unregistered off-screen speakers. Furthermore, we construct and release a dedicated speaker diarization benchmark for visual media that includes Chinese and English programs. Experimental results demonstrate that CineSRD achieves superior performance on the proposed benchmark and competitive results on conventional datasets, validating its robustness and generalizability in open-world visual media settings.
From Utterance to Vividity: Training Expressive Subtitle Translation LLM via Adaptive Local Preference Optimization
Feb 01, 2026The rapid development of Large Language Models (LLMs) has significantly enhanced the general capabilities of machine translation. However, as application scenarios become more complex, the limitations of LLMs in vertical domain translations are gradually becoming apparent. In this study, we focus on how to construct translation LLMs that meet the needs of domain customization. We take visual media subtitle translation as our topic and explore how to train expressive and vivid translation LLMs. We investigated the situations of subtitle translation and other domains of literal and liberal translation, verifying the reliability of LLM as reward model and evaluator for translation. Additionally, to train an expressive translation LLM, we constructed and released a multidirectional subtitle parallel corpus dataset and proposed the Adaptive Local Preference Optimization (ALPO) method to address fine-grained preference alignment. Experimental results demonstrate that ALPO achieves outstanding performance in multidimensional evaluation of translation quality.
Agentic Reward Modeling: Verifying GUI Agent via Online Proactive Interaction
Jan 31, 2026Reinforcement learning with verifiable rewards (RLVR) is pivotal for the continuous evolution of GUI agents, yet existing evaluation paradigms face significant limitations. Rule-based methods suffer from poor scalability and cannot handle open-ended tasks, while LLM-as-a-Judge approaches rely on passive visual observation, often failing to capture latent system states due to partial state observability. To address these challenges, we advocate for a paradigm shift from passive evaluation to Agentic Interactive Verification. We introduce VAGEN, a framework that employs a verifier agent equipped with interaction tools to autonomously plan verification strategies and proactively probe the environment for evidence of task completion. Leveraging the insight that GUI tasks are typically "easy to verify but hard to solve", VAGEN overcomes the bottlenecks of visual limitations. Experimental results on OSWorld-Verified and AndroidWorld benchmarks demonstrate that VAGEN significantly improves evaluation accuracy compared to LLM-as-a-Judge baselines and further enhances performance through test-time scaling strategies.
Hermes the Polyglot: A Unified Framework to Enhance Expressiveness for Multimodal Interlingual Subtitling
Jan 31, 2026Interlingual subtitling, which translates subtitles of visual media into a target language, is essential for entertainment localization but has not yet been explored in machine translation. Although Large Language Models (LLMs) have significantly advanced the general capabilities of machine translation, the distinctive characteristics of subtitle texts pose persistent challenges in interlingual subtitling, particularly regarding semantic coherence, pronoun and terminology translation, and translation expressiveness. To address these issues, we present Hermes, an LLM-based automated subtitling framework. Hermes integrates three modules: Speaker Diarization, Terminology Identification, and Expressiveness Enhancement, which effectively tackle the above challenges. Experiments demonstrate that Hermes achieves state-of-the-art diarization performance and generates expressive, contextually coherent translations, thereby advancing research in interlingual subtitling.
VL4Gaze: Unleashing Vision-Language Models for Gaze Following
Dec 23, 2025Human gaze provides essential cues for interpreting attention, intention, and social interaction in visual scenes, yet gaze understanding remains largely unexplored in current vision-language models (VLMs). While recent VLMs achieve strong scene-level reasoning across a range of visual tasks, there exists no benchmark that systematically evaluates or trains them for gaze interpretation, leaving open the question of whether gaze understanding can emerge from general-purpose vision-language pre-training. To address this gap, we introduce VL4Gaze, the first large-scale benchmark designed to investigate, evaluate, and unlock the potential of VLMs for gaze understanding. VL4Gaze contains 489K automatically generated question-answer pairs across 124K images and formulates gaze understanding as a unified VQA problem through four complementary tasks: (1) gaze object description, (2) gaze direction description, (3) gaze point location, and (4) ambiguous question recognition. We comprehensively evaluate both commercial and open-source VLMs under in-context learning and fine-tuning settings. The results show that even large-scale VLMs struggle to reliably infer gaze semantics and spatial localization without task-specific supervision. In contrast, training on VL4Gaze brings substantial and consistent improvements across all tasks, highlighting the importance of targeted multi-task supervision for developing gaze understanding capabilities in VLMs. We will release the dataset and code to support further research and development in this direction.
Fine-grained Video Dubbing Duration Alignment with Segment Supervised Preference Optimization
Aug 12, 2025Video dubbing aims to translate original speech in visual media programs from the source language to the target language, relying on neural machine translation and text-to-speech technologies. Due to varying information densities across languages, target speech often mismatches the source speech duration, causing audio-video synchronization issues that significantly impact viewer experience. In this study, we approach duration alignment in LLM-based video dubbing machine translation as a preference optimization problem. We propose the Segment Supervised Preference Optimization (SSPO) method, which employs a segment-wise sampling strategy and fine-grained loss to mitigate duration mismatches between source and target lines. Experimental results demonstrate that SSPO achieves superior performance in duration alignment tasks.
* This paper is accepted by ACL2025 (Main)
Suppressing Uncertainty in Gaze Estimation
Dec 17, 2024
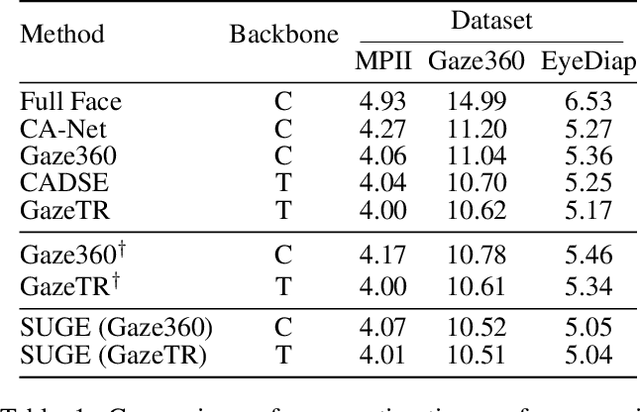
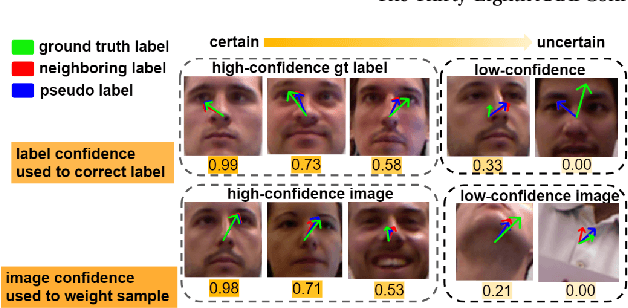
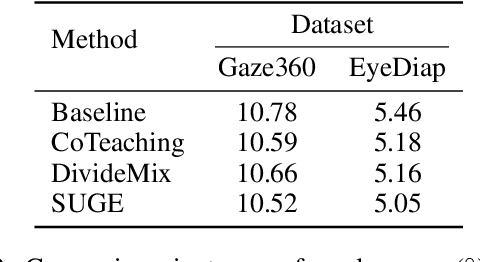
Uncertainty in gaze estimation manifests in two aspects: 1) low-quality images caused by occlusion, blurriness, inconsistent eye movements, or even non-face images; 2) incorrect labels resulting from the misalignment between the labeled and actual gaze points during the annotation process. Allowing these uncertainties to participate in training hinders the improvement of gaze estimation. To tackle these challenges, in this paper, we propose an effective solution, named Suppressing Uncertainty in Gaze Estimation (SUGE), which introduces a novel triplet-label consistency measurement to estimate and reduce the uncertainties. Specifically, for each training sample, we propose to estimate a novel ``neighboring label'' calculated by a linearly weighted projection from the neighbors to capture the similarity relationship between image features and their corresponding labels, which can be incorporated with the predicted pseudo label and ground-truth label for uncertainty estimation. By modeling such triplet-label consistency, we can measure the qualities of both images and labels, and further largely reduce the negative effects of unqualified images and wrong labels through our designed sample weighting and label correction strategies. Experimental results on the gaze estimation benchmarks indicate that our proposed SUGE achieves state-of-the-art performance.
Cross-Dataset Gaze Estimation by Evidential Inter-intra Fusion
Sep 07, 2024



Achieving accurate and reliable gaze predictions in complex and diverse environments remains challenging. Fortunately, it is straightforward to access diverse gaze datasets in real-world applications. We discover that training these datasets jointly can significantly improve the generalization of gaze estimation, which is overlooked in previous works. However, due to the inherent distribution shift across different datasets, simply mixing multiple dataset decreases the performance in the original domain despite gaining better generalization abilities. To address the problem of ``cross-dataset gaze estimation'', we propose a novel Evidential Inter-intra Fusion EIF framework, for training a cross-dataset model that performs well across all source and unseen domains. Specifically, we build independent single-dataset branches for various datasets where the data space is partitioned into overlapping subspaces within each dataset for local regression, and further create a cross-dataset branch to integrate the generalizable features from single-dataset branches. Furthermore, evidential regressors based on the Normal and Inverse-Gamma (NIG) distribution are designed to additionally provide uncertainty estimation apart from predicting gaze. Building upon this foundation, our proposed framework achieves both intra-evidential fusion among multiple local regressors within each dataset and inter-evidential fusion among multiple branches by Mixture \textbfof Normal Inverse-Gamma (MoNIG distribution. Experiments demonstrate that our method consistently achieves notable improvements in both source domains and unseen domains.
PCIE_LAM Solution for Ego4D Looking At Me Challenge
Jun 18, 2024



This report presents our team's 'PCIE_LAM' solution for the Ego4D Looking At Me Challenge at CVPR2024. The main goal of the challenge is to accurately determine if a person in the scene is looking at the camera wearer, based on a video where the faces of social partners have been localized. Our proposed solution, InternLSTM, consists of an InternVL image encoder and a Bi-LSTM network. The InternVL extracts spatial features, while the Bi-LSTM extracts temporal features. However, this task is highly challenging due to the distance between the person in the scene and the camera movement, which results in significant blurring in the face image. To address the complexity of the task, we implemented a Gaze Smoothing filter to eliminate noise or spikes from the output. Our approach achieved the 1st position in the looking at me challenge with 0.81 mAP and 0.93 accuracy rate. Code is available at https://github.com/KanokphanL/Ego4D_LAM_InternLSTM
EduNLP: Towards a Unified and Modularized Library for Educational Resources
Jun 04, 2024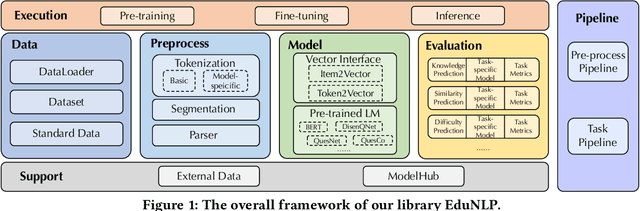
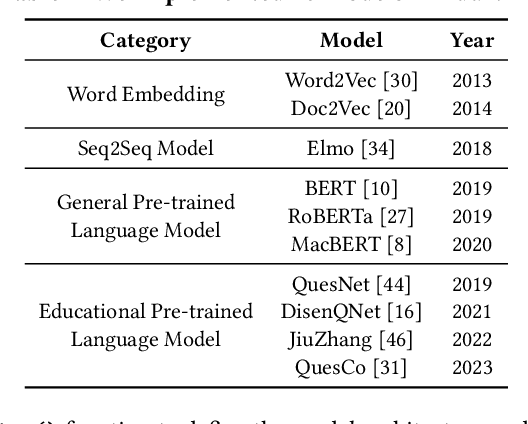
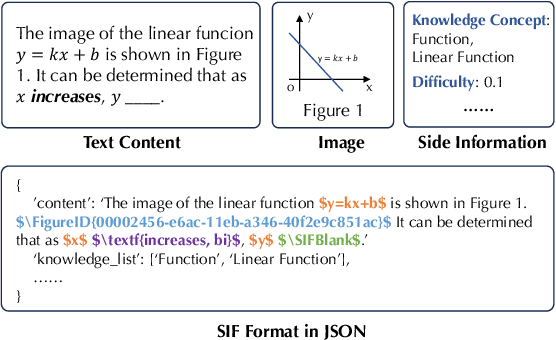
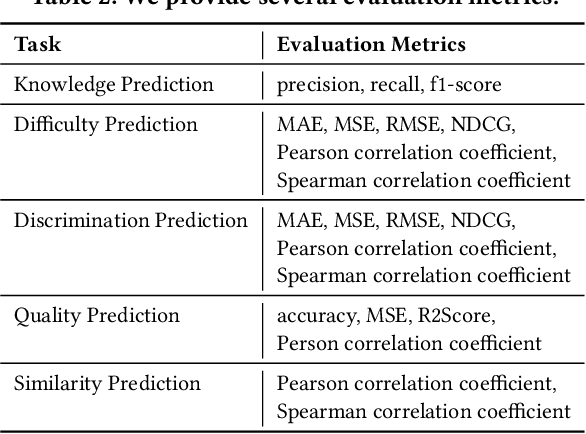
Educational resource understanding is vital to online learning platforms, which have demonstrated growing applications recently. However, researchers and developers always struggle with using existing general natural language toolkits or domain-specific models. The issue raises a need to develop an effective and easy-to-use one that benefits AI education-related research and applications. To bridge this gap, we present a unified, modularized, and extensive library, EduNLP, focusing on educational resource understanding. In the library, we decouple the whole workflow to four key modules with consistent interfaces including data configuration, processing, model implementation, and model evaluation. We also provide a configurable pipeline to unify the data usage and model usage in standard ways, where users can customize their own needs. For the current version, we primarily provide 10 typical models from four categories, and 5 common downstream-evaluation tasks in the education domain on 8 subjects for users' usage. The project is released at: https://github.com/bigdata-ustc/EduNLP.