 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBest-of-Both-Worlds for Heavy-Tailed Markov Decision Processes
Feb 03, 2026We investigate episodic Markov Decision Processes with heavy-tailed feedback (HTMDPs). Existing approaches for HTMDPs are conservative in stochastic environments and lack adaptivity in adversarial regimes. In this work, we propose algorithms HT-FTRL-OM and HT-FTRL-UOB for HTMDPs that achieve Best-of-Both-Worlds (BoBW) guarantees: instance-independent regret in adversarial environments and logarithmic instance-dependent regret in self-bounding (including the stochastic case) environments. For the known transition setting, HT-FTRL-OM applies the Follow-The-Regularized-Leader (FTRL) framework over occupancy measures with novel skipping loss estimators, achieving a $\widetilde{O}(T^{1/α})$ regret bound in adversarial regimes and a $O(\log T)$ regret in stochastic regimes. Building upon this framework, we develop a novel algorithm HT-FTRL-UOB to tackle the more challenging unknown-transition setting. This algorithm employs a pessimistic skipping loss estimator and achieves a $\widetilde{O}(T^{1/α} + \sqrt{T})$ regret in adversarial regimes and a $O(\log^2(T))$ regret in stochastic regimes. Our analysis overcomes key barriers through several technical insights, including a local control mechanism for heavy-tailed shifted losses, a new suboptimal-mass propagation principle, and a novel regret decomposition that isolates transition uncertainty from heavy-tailed estimation errors and skipping bias.
Reinforcement Learning with Segment Feedback
Feb 03, 2025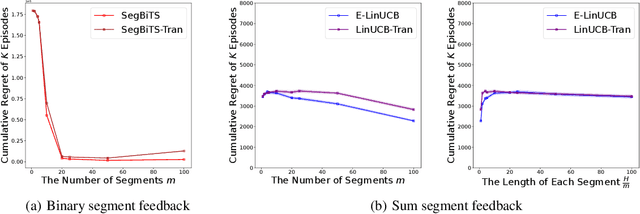
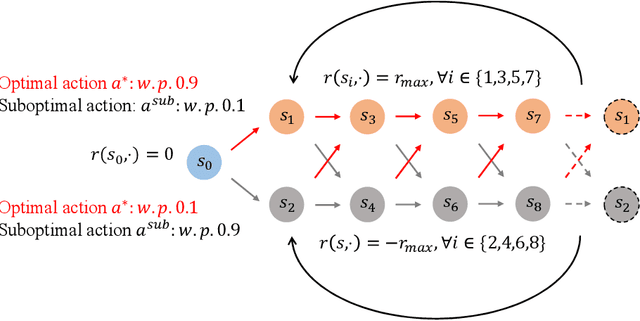
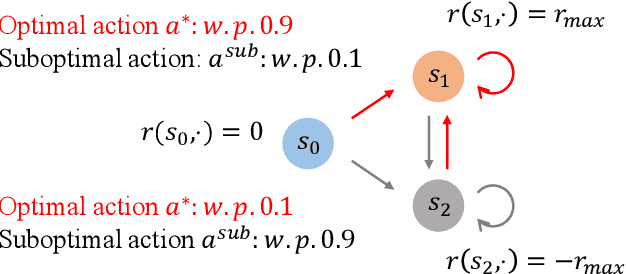
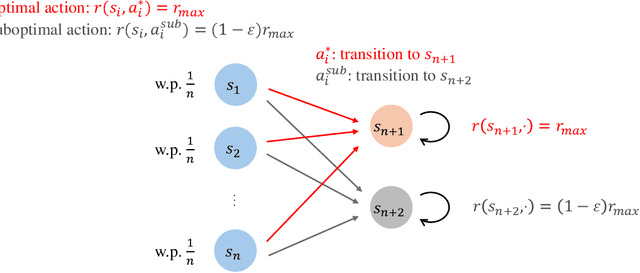
Standard reinforcement learning (RL) assumes that an agent can observe a reward for each state-action pair. However, in practical applications, it is often difficult and costly to collect a reward for each state-action pair. While there have been several works considering RL with trajectory feedback, it is unclear if trajectory feedback is inefficient for learning when trajectories are long. In this work, we consider a model named RL with segment feedback, which offers a general paradigm filling the gap between per-state-action feedback and trajectory feedback. In this model, we consider an episodic Markov decision process (MDP), where each episode is divided into $m$ segments, and the agent observes reward feedback only at the end of each segment. Under this model, we study two popular feedback settings: binary feedback and sum feedback, where the agent observes a binary outcome and a reward sum according to the underlying reward function, respectively. To investigate the impact of the number of segments $m$ on learning performance, we design efficient algorithms and establish regret upper and lower bounds for both feedback settings. Our theoretical and experimental results show that: under binary feedback, increasing the number of segments $m$ decreases the regret at an exponential rate; in contrast, surprisingly, under sum feedback, increasing $m$ does not reduce the regret significantly.
Exploration-Driven Policy Optimization in RLHF: Theoretical Insights on Efficient Data Utilization
Feb 15, 2024
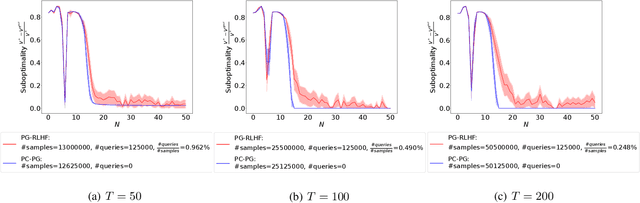
Reinforcement Learning from Human Feedback (RLHF) has achieved impressive empirical successes while relying on a small amount of human feedback. However, there is limited theoretical justification for this phenomenon. Additionally, most recent studies focus on value-based algorithms despite the recent empirical successes of policy-based algorithms. In this work, we consider an RLHF algorithm based on policy optimization (PO-RLHF). The algorithm is based on the popular Policy Cover-Policy Gradient (PC-PG) algorithm, which assumes knowledge of the reward function. In PO-RLHF, knowledge of the reward function is not assumed and the algorithm relies on trajectory-based comparison feedback to infer the reward function. We provide performance bounds for PO-RLHF with low query complexity, which provides insight into why a small amount of human feedback may be sufficient to get good performance with RLHF. A key novelty is our trajectory-level elliptical potential analysis technique used to infer reward function parameters when comparison queries rather than reward observations are used. We provide and analyze algorithms in two settings: linear and neural function approximation, PG-RLHF and NN-PG-RLHF, respectively.
Cascading Reinforcement Learning
Jan 17, 2024Cascading bandits have gained popularity in recent years due to their applicability to recommendation systems and online advertising. In the cascading bandit model, at each timestep, an agent recommends an ordered subset of items (called an item list) from a pool of items, each associated with an unknown attraction probability. Then, the user examines the list, and clicks the first attractive item (if any), and after that, the agent receives a reward. The goal of the agent is to maximize the expected cumulative reward. However, the prior literature on cascading bandits ignores the influences of user states (e.g., historical behaviors) on recommendations and the change of states as the session proceeds. Motivated by this fact, we propose a generalized cascading RL framework, which considers the impact of user states and state transition into decisions. In cascading RL, we need to select items not only with large attraction probabilities but also leading to good successor states. This imposes a huge computational challenge due to the combinatorial action space. To tackle this challenge, we delve into the properties of value functions, and design an oracle BestPerm to efficiently find the optimal item list. Equipped with BestPerm, we develop two algorithms CascadingVI and CascadingBPI, which are both computationally-efficient and sample-efficient, and provide near-optimal regret and sample complexity guarantees. Furthermore, we present experiments to show the improved computational and sample efficiencies of our algorithms compared to straightforward adaptations of existing RL algorithms in practice.
Provably Efficient Iterated CVaR Reinforcement Learning with Function Approximation
Jul 06, 2023



Risk-sensitive reinforcement learning (RL) aims to optimize policies that balance the expected reward and risk. In this paper, we investigate a novel risk-sensitive RL formulation with an Iterated Conditional Value-at-Risk (CVaR) objective under linear and general function approximations. This new formulation, named ICVaR-RL with function approximation, provides a principled way to guarantee safety at each decision step. For ICVaR-RL with linear function approximation, we propose a computationally efficient algorithm ICVaR-L, which achieves an $\widetilde{O}(\sqrt{\alpha^{-(H+1)}(d^2H^4+dH^6)K})$ regret, where $\alpha$ is the risk level, $d$ is the dimension of state-action features, $H$ is the length of each episode, and $K$ is the number of episodes. We also establish a matching lower bound $\Omega(\sqrt{\alpha^{-(H-1)}d^2K})$ to validate the optimality of ICVaR-L with respect to $d$ and $K$. For ICVaR-RL with general function approximation, we propose algorithm ICVaR-G, which achieves an $\widetilde{O}(\sqrt{\alpha^{-(H+1)}DH^4K})$ regret, where $D$ is a dimensional parameter that depends on the eluder dimension and covering number. Furthermore, our analysis provides several novel techniques for risk-sensitive RL, including an efficient approximation of the CVaR operator, a new ridge regression with CVaR-adapted features, and a refined elliptical potential lemma.
Multi-task Representation Learning for Pure Exploration in Linear Bandits
Feb 09, 2023
Despite the recent success of representation learning in sequential decision making, the study of the pure exploration scenario (i.e., identify the best option and minimize the sample complexity) is still limited. In this paper, we study multi-task representation learning for best arm identification in linear bandits (RepBAI-LB) and best policy identification in contextual linear bandits (RepBPI-CLB), two popular pure exploration settings with wide applications, e.g., clinical trials and web content optimization. In these two problems, all tasks share a common low-dimensional linear representation, and our goal is to leverage this feature to accelerate the best arm (policy) identification process for all tasks. For these problems, we design computationally and sample efficient algorithms DouExpDes and C-DouExpDes, which perform double experimental designs to plan optimal sample allocations for learning the global representation. We show that by learning the common representation among tasks, our sample complexity is significantly better than that of the native approach which solves tasks independently. To the best of our knowledge, this is the first work to demonstrate the benefits of representation learning for multi-task pure exploration.
Dueling Bandits: From Two-dueling to Multi-dueling
Nov 16, 2022We study a general multi-dueling bandit problem, where an agent compares multiple options simultaneously and aims to minimize the regret due to selecting suboptimal arms. This setting generalizes the traditional two-dueling bandit problem and finds many real-world applications involving subjective feedback on multiple options. We start with the two-dueling bandit setting and propose two efficient algorithms, DoublerBAI and MultiSBM-Feedback. DoublerBAI provides a generic schema for translating known results on best arm identification algorithms to the dueling bandit problem, and achieves a regret bound of $O(\ln T)$. MultiSBM-Feedback not only has an optimal $O(\ln T)$ regret, but also reduces the constant factor by almost a half compared to benchmark results. Then, we consider the general multi-dueling case and develop an efficient algorithm MultiRUCB. Using a novel finite-time regret analysis for the general multi-dueling bandit problem, we show that MultiRUCB also achieves an $O(\ln T)$ regret bound and the bound tightens as the capacity of the comparison set increases. Based on both synthetic and real-world datasets, we empirically demonstrate that our algorithms outperform existing algorithms.
Risk-Sensitive Reinforcement Learning: Iterated CVaR and the Worst Path
Jun 06, 2022
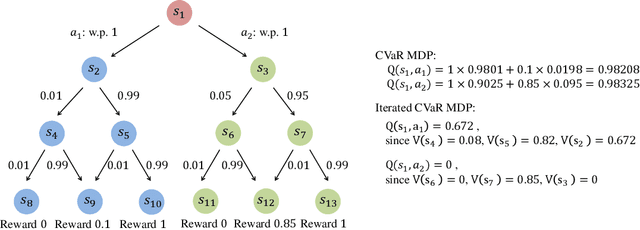
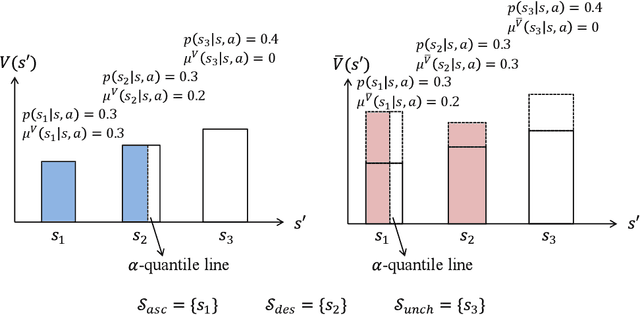
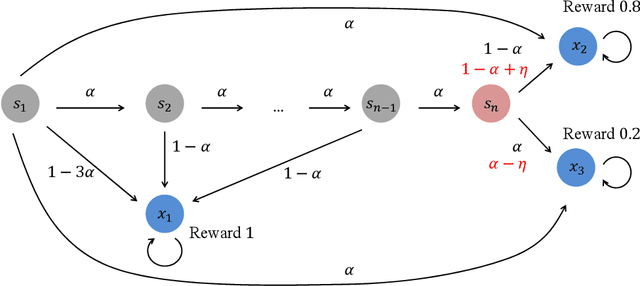
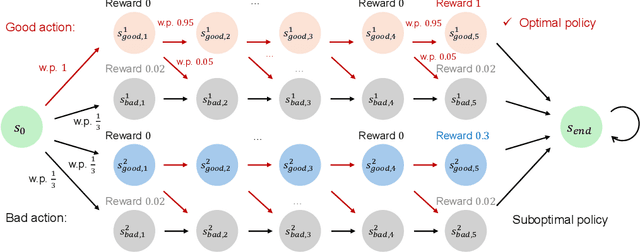
In this paper, we study a novel episodic risk-sensitive Reinforcement Learning (RL) problem, named Iterated CVaR RL, where the objective is to maximize the tail of the reward-to-go at each step. Different from existing risk-aware RL formulations, Iterated CVaR RL focuses on safety-at-all-time, by enabling the agent to tightly control the risk of getting into catastrophic situations at each stage, and is applicable to important risk-sensitive tasks that demand strong safety guarantees throughout the decision process, such as autonomous driving, clinical treatment planning and robotics. We investigate Iterated CVaR RL with two performance metrics, i.e., Regret Minimization and Best Policy Identification. For both metrics, we design efficient algorithms ICVaR-RM and ICVaR-BPI, respectively, and provide matching upper and lower bounds with respect to the number of episodes $K$. We also investigate an interesting limiting case of Iterated CVaR RL, called Worst Path RL, where the objective becomes to maximize the minimum possible cumulative reward, and propose an efficient algorithm with constant upper and lower bounds. Finally, the techniques we develop for bounding the change of CVaR due to the value function shift and decomposing the regret via a distorted visitation distribution are novel and can find applications in other risk-sensitive online learning problems.
Branching Reinforcement Learning
Feb 16, 2022
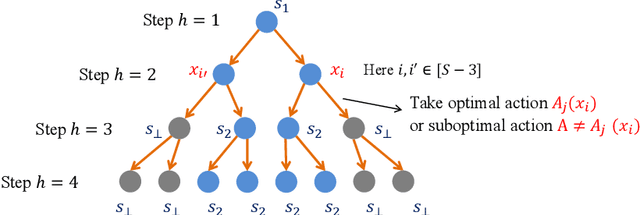
In this paper, we propose a novel Branching Reinforcement Learning (Branching RL) model, and investigate both Regret Minimization (RM) and Reward-Free Exploration (RFE) metrics for this model. Unlike standard RL where the trajectory of each episode is a single $H$-step path, branching RL allows an agent to take multiple base actions in a state such that transitions branch out to multiple successor states correspondingly, and thus it generates a tree-structured trajectory. This model finds important applications in hierarchical recommendation systems and online advertising. For branching RL, we establish new Bellman equations and key lemmas, i.e., branching value difference lemma and branching law of total variance, and also bound the total variance by only $O(H^2)$ under an exponentially-large trajectory. For RM and RFE metrics, we propose computationally efficient algorithms BranchVI and BranchRFE, respectively, and derive nearly matching upper and lower bounds. Our results are only polynomial in problem parameters despite exponentially-large trajectories.
Collaborative Pure Exploration in Kernel Bandit
Oct 29, 2021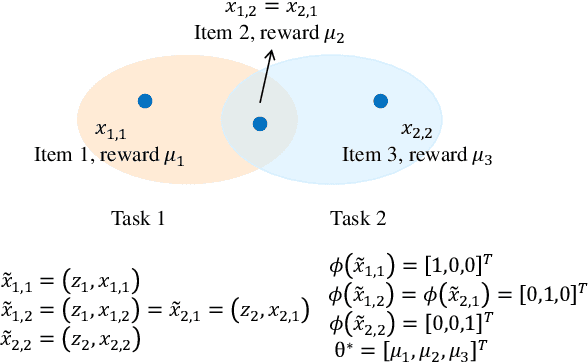

In this paper, we formulate a Collaborative Pure Exploration in Kernel Bandit problem (CoPE-KB), which provides a novel model for multi-agent multi-task decision making under limited communication and general reward functions, and is applicable to many online learning tasks, e.g., recommendation systems and network scheduling. We consider two settings of CoPE-KB, i.e., Fixed-Confidence (FC) and Fixed-Budget (FB), and design two optimal algorithms CoopKernelFC (for FC) and CoopKernelFB (for FB). Our algorithms are equipped with innovative and efficient kernelized estimators to simultaneously achieve computation and communication efficiency. Matching upper and lower bounds under both the statistical and communication metrics are established to demonstrate the optimality of our algorithms. The theoretical bounds successfully quantify the influences of task similarities on learning acceleration and only depend on the effective dimension of the kernelized feature space. Our analytical techniques, including data dimension decomposition, linear structured instance transformation and (communication) round-speedup induction, are novel and applicable to other bandit problems. Empirical evaluations are provided to validate our theoretical results and demonstrate the performance superiority of our algorithms.