 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImperfect Digital Twin Assisted Low Cost Reinforcement Training for Multi-UAV Networks
Oct 25, 2023


Deep Reinforcement Learning (DRL) is widely used to optimize the performance of multi-UAV networks. However, the training of DRL relies on the frequent interactions between the UAVs and the environment, which consumes lots of energy due to the flying and communication of UAVs in practical experiments. Inspired by the growing digital twin (DT) technology, which can simulate the performance of algorithms in the digital space constructed by coping features of the physical space, the DT is introduced to reduce the costs of practical training, e.g., energy and hardware purchases. Different from previous DT-assisted works with an assumption of perfect reflecting real physics by virtual digital, we consider an imperfect DT model with deviations for assisting the training of multi-UAV networks. Remarkably, to trade off the training cost, DT construction cost, and the impact of deviations of DT on training, the natural and virtually generated UAV mixing deployment method is proposed. Two cascade neural networks (NN) are used to optimize the joint number of virtually generated UAVs, the DT construction cost, and the performance of multi-UAV networks. These two NNs are trained by unsupervised and reinforcement learning, both low-cost label-free training methods. Simulation results show the training cost can significantly decrease while guaranteeing the training performance. This implies that an efficient decision can be made with imperfect DTs in multi-UAV networks.
Digital Twin-Assisted Efficient Reinforcement Learning for Edge Task Scheduling
Aug 02, 2022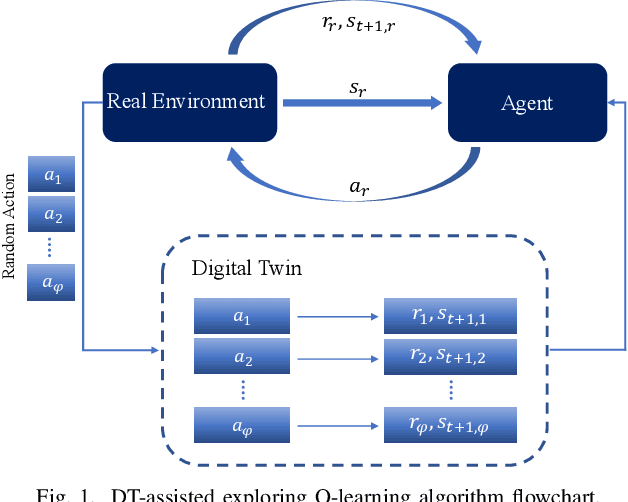
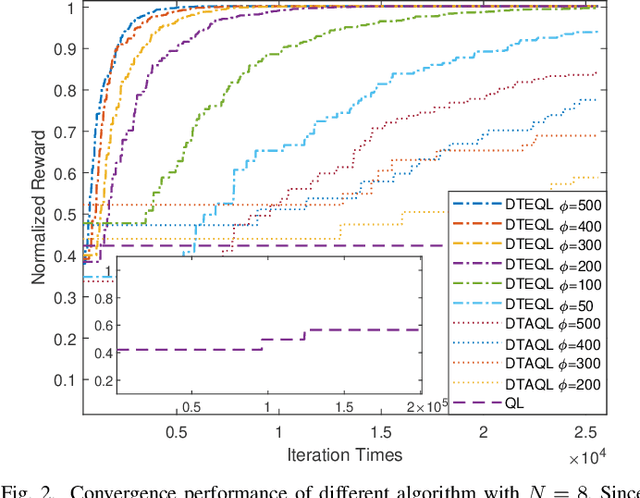


Task scheduling is a critical problem when one user offloads multiple different tasks to the edge server. When a user has multiple tasks to offload and only one task can be transmitted to server at a time, while server processes tasks according to the transmission order, the problem is NP-hard. However, it is difficult for traditional optimization methods to quickly obtain the optimal solution, while approaches based on reinforcement learning face with the challenge of excessively large action space and slow convergence. In this paper, we propose a Digital Twin (DT)-assisted RL-based task scheduling method in order to improve the performance and convergence of the RL. We use DT to simulate the results of different decisions made by the agent, so that one agent can try multiple actions at a time, or, similarly, multiple agents can interact with environment in parallel in DT. In this way, the exploration efficiency of RL can be significantly improved via DT, and thus RL can converges faster and local optimality is less likely to happen. Particularly, two algorithms are designed to made task scheduling decisions, i.e., DT-assisted asynchronous Q-learning (DTAQL) and DT-assisted exploring Q-learning (DTEQL). Simulation results show that both algorithms significantly improve the convergence speed of Q-learning by increasing the exploration efficiency.