 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal Byte Fusion for Neural Machine Translation
Paper and Code
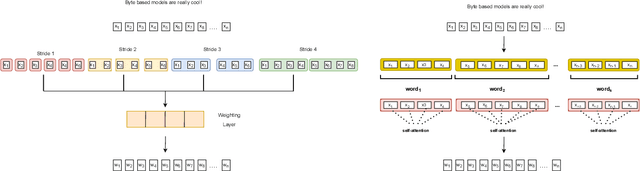
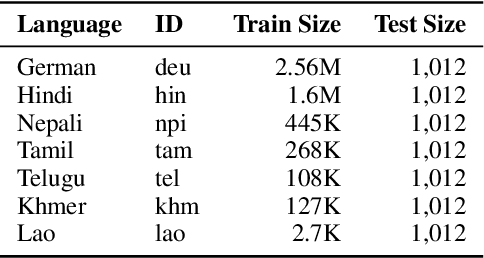
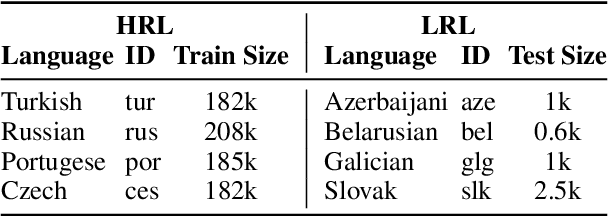
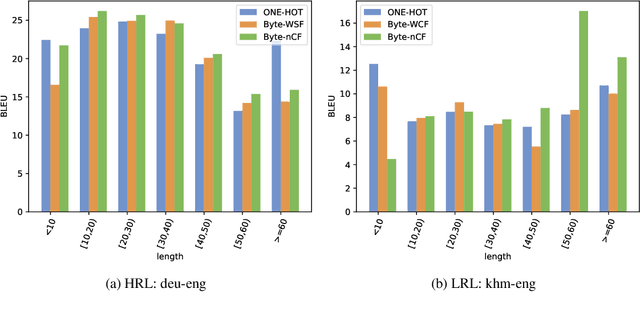
Subword tokenization schemes are the dominant technique used in current NLP models. However, such schemes can be rigid and tokenizers built on one corpus do not adapt well to other parallel corpora. It has also been observed that in multilingual corpora, subword tokenization schemes over-segment low-resource languages leading to a drop in translation performance. A simple alternative to subword tokenizers is byte-based methods i.e. tokenization into byte sequences using encoding schemes such as UTF-8. Byte tokens often represent inputs at a sub-character granularity i.e. one character can be represented by a sequence of multiple byte tokens. This results in byte sequences that are significantly longer than character sequences. Enforcing aggregation of local information in the lower layers can guide the model to build higher-level semantic information. We propose a Local Byte Fusion (LOBEF) method for byte-based machine translation -- utilizing byte $n$-gram and word boundaries -- to aggregate local semantic information. Extensive experiments on multilingual translation, zero-shot cross-lingual transfer, and domain adaptation reveal a consistent improvement over traditional byte-based models and even over subword techniques. Further analysis also indicates that our byte-based models are parameter-efficient and can be trained faster than subword models.