 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy Profiles for Private Selection
Feb 09, 2024



Private selection mechanisms (e.g., Report Noisy Max, Sparse Vector) are fundamental primitives of differentially private (DP) data analysis with wide applications to private query release, voting, and hyperparameter tuning. Recent work (Liu and Talwar, 2019; Papernot and Steinke, 2022) has made significant progress in both generalizing private selection mechanisms and tightening their privacy analysis using modern numerical privacy accounting tools, e.g., R\'enyi DP. But R\'enyi DP is known to be lossy when $(\epsilon,\delta)$-DP is ultimately needed, and there is a trend to close the gap by directly handling privacy profiles, i.e., $\delta$ as a function of $\epsilon$ or its equivalent dual form known as $f$-DPs. In this paper, we work out an easy-to-use recipe that bounds the privacy profiles of ReportNoisyMax and PrivateTuning using the privacy profiles of the base algorithms they corral. Numerically, our approach improves over the RDP-based accounting in all regimes of interest and leads to substantial benefits in end-to-end private learning experiments. Our analysis also suggests new distributions, e.g., binomial distribution for randomizing the number of rounds that leads to more substantial improvements in certain regimes.
Improving the Privacy and Practicality of Objective Perturbation for Differentially Private Linear Learners
Dec 31, 2023In the arena of privacy-preserving machine learning, differentially private stochastic gradient descent (DP-SGD) has outstripped the objective perturbation mechanism in popularity and interest. Though unrivaled in versatility, DP-SGD requires a non-trivial privacy overhead (for privately tuning the model's hyperparameters) and a computational complexity which might be extravagant for simple models such as linear and logistic regression. This paper revamps the objective perturbation mechanism with tighter privacy analyses and new computational tools that boost it to perform competitively with DP-SGD on unconstrained convex generalized linear problems.
Tractable MCMC for Private Learning with Pure and Gaussian Differential Privacy
Oct 23, 2023Posterior sampling, i.e., exponential mechanism to sample from the posterior distribution, provides $\varepsilon$-pure differential privacy (DP) guarantees and does not suffer from potentially unbounded privacy breach introduced by $(\varepsilon,\delta)$-approximate DP. In practice, however, one needs to apply approximate sampling methods such as Markov chain Monte Carlo (MCMC), thus re-introducing the unappealing $\delta$-approximation error into the privacy guarantees. To bridge this gap, we propose the Approximate SAample Perturbation (abbr. ASAP) algorithm which perturbs an MCMC sample with noise proportional to its Wasserstein-infinity ($W_\infty$) distance from a reference distribution that satisfies pure DP or pure Gaussian DP (i.e., $\delta=0$). We then leverage a Metropolis-Hastings algorithm to generate the sample and prove that the algorithm converges in W$_\infty$ distance. We show that by combining our new techniques with a careful localization step, we obtain the first nearly linear-time algorithm that achieves the optimal rates in the DP-ERM problem with strongly convex and smooth losses.
Generalized PTR: User-Friendly Recipes for Data-Adaptive Algorithms with Differential Privacy
Dec 31, 2022The ''Propose-Test-Release'' (PTR) framework is a classic recipe for designing differentially private (DP) algorithms that are data-adaptive, i.e. those that add less noise when the input dataset is nice. We extend PTR to a more general setting by privately testing data-dependent privacy losses rather than local sensitivity, hence making it applicable beyond the standard noise-adding mechanisms, e.g. to queries with unbounded or undefined sensitivity. We demonstrate the versatility of generalized PTR using private linear regression as a case study. Additionally, we apply our algorithm to solve an open problem from ''Private Aggregation of Teacher Ensembles (PATE)'' -- privately releasing the entire model with a delicate data-dependent analysis.
Privately Publishable Per-instance Privacy
Nov 03, 2021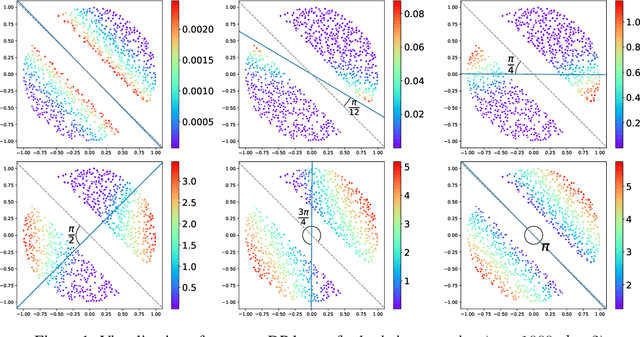
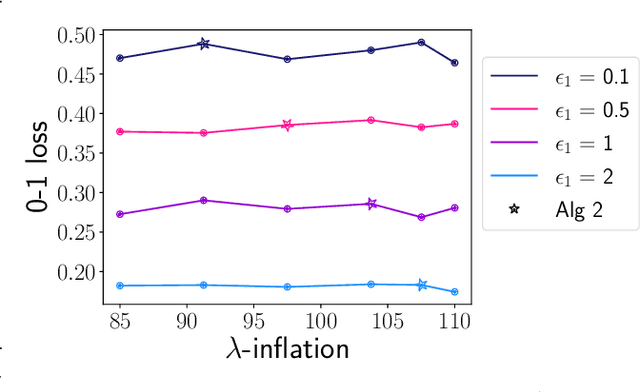
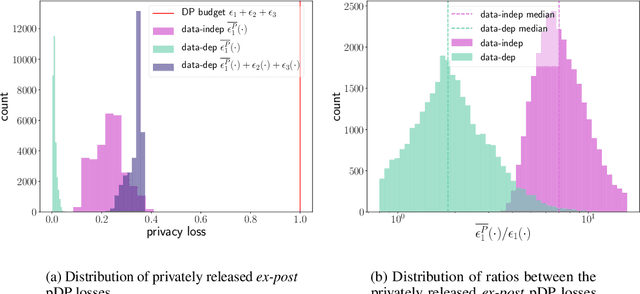
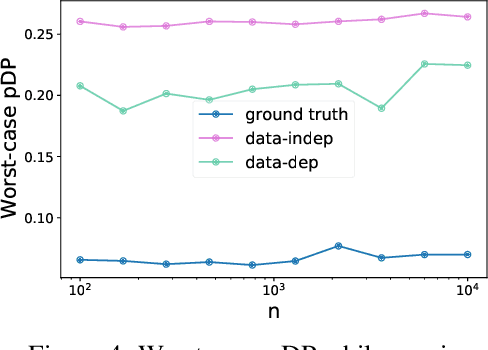
We consider how to privately share the personalized privacy losses incurred by objective perturbation, using per-instance differential privacy (pDP). Standard differential privacy (DP) gives us a worst-case bound that might be orders of magnitude larger than the privacy loss to a particular individual relative to a fixed dataset. The pDP framework provides a more fine-grained analysis of the privacy guarantee to a target individual, but the per-instance privacy loss itself might be a function of sensitive data. In this paper, we analyze the per-instance privacy loss of releasing a private empirical risk minimizer learned via objective perturbation, and propose a group of methods to privately and accurately publish the pDP losses at little to no additional privacy cost.
Tree++: Truncated Tree Based Graph Kernels
Feb 23, 2020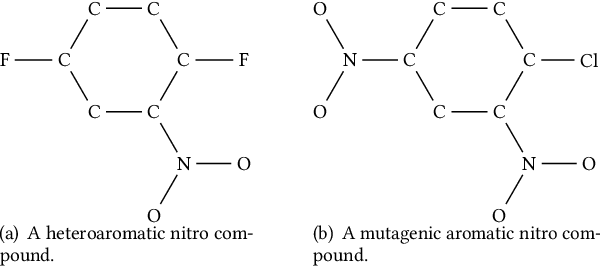
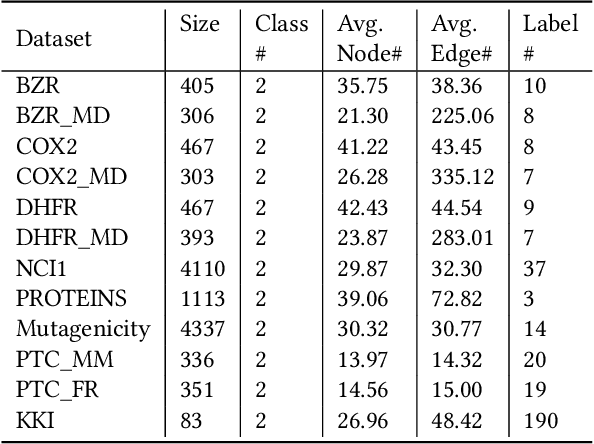
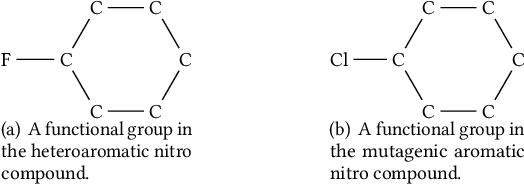
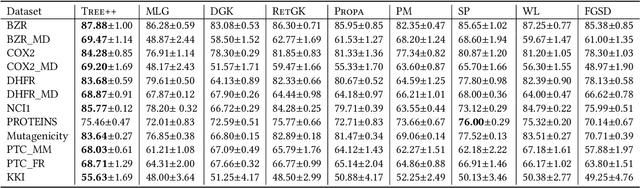
Graph-structured data arise ubiquitously in many application domains. A fundamental problem is to quantify their similarities. Graph kernels are often used for this purpose, which decompose graphs into substructures and compare these substructures. However, most of the existing graph kernels do not have the property of scale-adaptivity, i.e., they cannot compare graphs at multiple levels of granularities. Many real-world graphs such as molecules exhibit structure at varying levels of granularities. To tackle this problem, we propose a new graph kernel called Tree++ in this paper. At the heart of Tree++ is a graph kernel called the path-pattern graph kernel. The path-pattern graph kernel first builds a truncated BFS tree rooted at each vertex and then uses paths from the root to every vertex in the truncated BFS tree as features to represent graphs. The path-pattern graph kernel can only capture graph similarity at fine granularities. In order to capture graph similarity at coarse granularities, we incorporate a new concept called super path into it. The super path contains truncated BFS trees rooted at the vertices in a path. Our evaluation on a variety of real-world graphs demonstrates that Tree++ achieves the best classification accuracy compared with previous graph kernels.