 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplete Dictionary Learning via $\ell^4$-Norm Maximization over the Orthogonal Group
Paper and Code
Jul 10, 2019
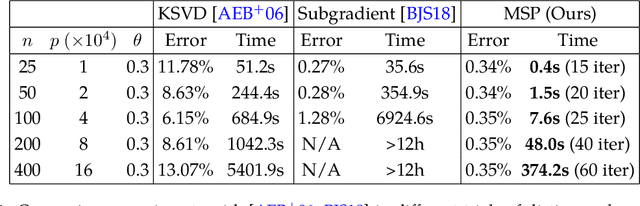
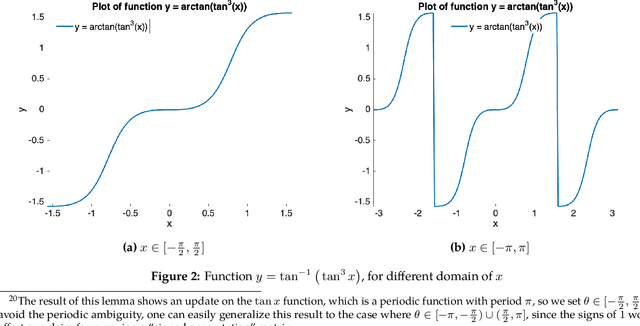
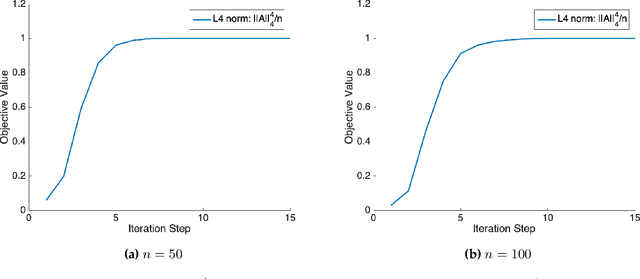
This paper considers the fundamental problem of learning a complete (orthogonal) dictionary from samples of sparsely generated signals. Most existing methods solve the dictionary (and sparse representations) based on heuristic algorithms, usually without theoretical guarantees for either optimality or complexity. The recent $\ell^1$-minimization based methods do provide such guarantees but the associated algorithms recover the dictionary one column at a time. In this work, we propose a new formulation that maximizes the $\ell^4$-norm over the orthogonal group, to learn the entire dictionary. We prove that under a random data model, with nearly minimum sample complexity, the global optima of the $\ell^4$ norm are very close to signed permutations of the ground truth. Inspired by this observation, we give a conceptually simple and yet effective algorithm based on "matching, stretching, and projection" (MSP). The algorithm provably converges locally at a superlinear (cubic) rate and cost per iteration is merely an SVD. In addition to strong theoretical guarantees, experiments show that the new algorithm is significantly more efficient and effective than existing methods, including KSVD and $\ell^1$-based methods. Preliminary experimental results on mixed real imagery data clearly demonstrate advantages of so learned dictionary over classic PCA bases.