 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Do Vision-Language Models Process Conflicting Information Across Modalities?
Jul 02, 2025AI models are increasingly required to be multimodal, integrating disparate input streams into a coherent state representation on which subsequent behaviors and actions can be based. This paper seeks to understand how such models behave when input streams present conflicting information. Focusing specifically on vision-language models, we provide inconsistent inputs (e.g., an image of a dog paired with the caption "A photo of a cat") and ask the model to report the information present in one of the specific modalities (e.g., "What does the caption say / What is in the image?"). We find that models often favor one modality over the other, e.g., reporting the image regardless of what the caption says, but that different models differ in which modality they favor. We find evidence that the behaviorally preferred modality is evident in the internal representational structure of the model, and that specific attention heads can restructure the representations to favor one modality over the other. Moreover, we find modality-agnostic "router heads" which appear to promote answers about the modality requested in the instruction, and which can be manipulated or transferred in order to improve performance across datasets and modalities. Together, the work provides essential steps towards identifying and controlling if and how models detect and resolve conflicting signals within complex multimodal environments.
mOthello: When Do Cross-Lingual Representation Alignment and Cross-Lingual Transfer Emerge in Multilingual Models?
Apr 18, 2024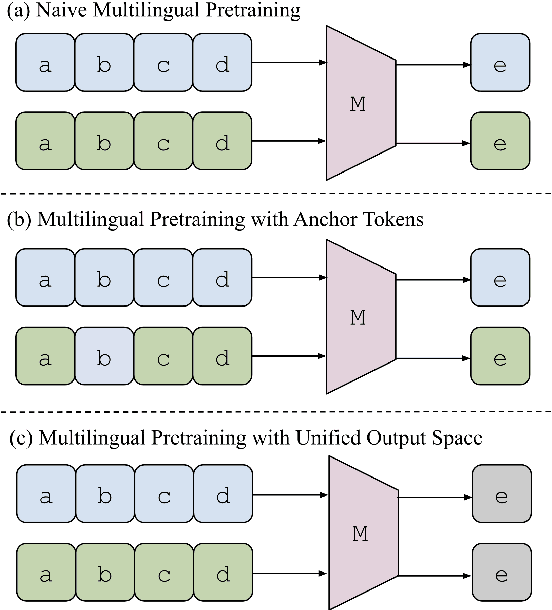

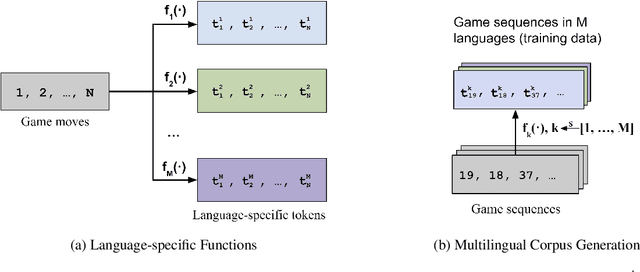

Many pretrained multilingual models exhibit cross-lingual transfer ability, which is often attributed to a learned language-neutral representation during pretraining. However, it remains unclear what factors contribute to the learning of a language-neutral representation, and whether the learned language-neutral representation suffices to facilitate cross-lingual transfer. We propose a synthetic task, Multilingual Othello (mOthello), as a testbed to delve into these two questions. We find that: (1) models trained with naive multilingual pretraining fail to learn a language-neutral representation across all input languages; (2) the introduction of "anchor tokens" (i.e., lexical items that are identical across languages) helps cross-lingual representation alignment; and (3) the learning of a language-neutral representation alone is not sufficient to facilitate cross-lingual transfer. Based on our findings, we propose a novel approach - multilingual pretraining with unified output space - that both induces the learning of language-neutral representation and facilitates cross-lingual transfer.