 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMS4UI: A Dataset for Multi-modal Summarization of User Interface Instructional Videos
Jun 14, 2025We study multi-modal summarization for instructional videos, whose goal is to provide users an efficient way to learn skills in the form of text instructions and key video frames. We observe that existing benchmarks focus on generic semantic-level video summarization, and are not suitable for providing step-by-step executable instructions and illustrations, both of which are crucial for instructional videos. We propose a novel benchmark for user interface (UI) instructional video summarization to fill the gap. We collect a dataset of 2,413 UI instructional videos, which spans over 167 hours. These videos are manually annotated for video segmentation, text summarization, and video summarization, which enable the comprehensive evaluations for concise and executable video summarization. We conduct extensive experiments on our collected MS4UI dataset, which suggest that state-of-the-art multi-modal summarization methods struggle on UI video summarization, and highlight the importance of new methods for UI instructional video summarization.
Do Pre-trained Vision-Language Models Encode Object States?
Sep 16, 2024



For a vision-language model (VLM) to understand the physical world, such as cause and effect, a first step is to capture the temporal dynamics of the visual world, for example how the physical states of objects evolve over time (e.g. a whole apple into a sliced apple). Our paper aims to investigate if VLMs pre-trained on web-scale data learn to encode object states, which can be extracted with zero-shot text prompts. We curate an object state recognition dataset ChangeIt-Frames, and evaluate nine open-source VLMs, including models trained with contrastive and generative objectives. We observe that while these state-of-the-art vision-language models can reliably perform object recognition, they consistently fail to accurately distinguish the objects' physical states. Through extensive experiments, we identify three areas for improvements for VLMs to better encode object states, namely the quality of object localization, the architecture to bind concepts to objects, and the objective to learn discriminative visual and language encoders on object states. Data and code are released.
Pre-trained Vision-Language Models Learn Discoverable Visual Concepts
Apr 19, 2024Do vision-language models (VLMs) pre-trained to caption an image of a "durian" learn visual concepts such as "brown" (color) and "spiky" (texture) at the same time? We aim to answer this question as visual concepts learned "for free" would enable wide applications such as neuro-symbolic reasoning or human-interpretable object classification. We assume that the visual concepts, if captured by pre-trained VLMs, can be extracted by their vision-language interface with text-based concept prompts. We observe that recent works prompting VLMs with concepts often differ in their strategies to define and evaluate the visual concepts, leading to conflicting conclusions. We propose a new concept definition strategy based on two observations: First, certain concept prompts include shortcuts that recognize correct concepts for wrong reasons; Second, multimodal information (e.g. visual discriminativeness, and textual knowledge) should be leveraged when selecting the concepts. Our proposed concept discovery and learning (CDL) framework is thus designed to identify a diverse list of generic visual concepts (e.g. "spiky" as opposed to "spiky durian"), which are ranked and selected based on visual and language mutual information. We carefully design quantitative and human evaluations of the discovered concepts on six diverse visual recognition datasets, which confirm that pre-trained VLMs do learn visual concepts that provide accurate and thorough descriptions for the recognized objects. All code and models are publicly released.
Learning to Attack: Towards Textual Adversarial Attacking in Real-world Situations
Sep 19, 2020
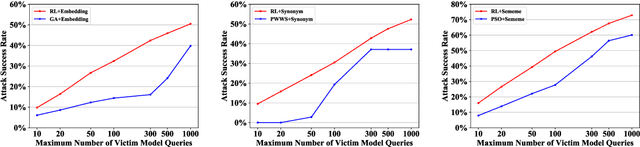
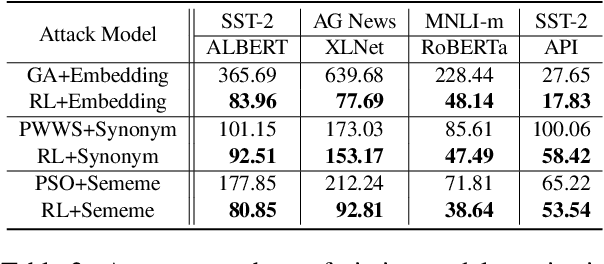
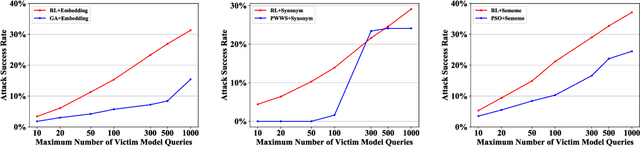
Adversarial attacking aims to fool deep neural networks with adversarial examples. In the field of natural language processing, various textual adversarial attack models have been proposed, varying in the accessibility to the victim model. Among them, the attack models that only require the output of the victim model are more fit for real-world situations of adversarial attacking. However, to achieve high attack performance, these models usually need to query the victim model too many times, which is neither efficient nor viable in practice. To tackle this problem, we propose a reinforcement learning based attack model, which can learn from attack history and launch attacks more efficiently. In experiments, we evaluate our model by attacking several state-of-the-art models on the benchmark datasets of multiple tasks including sentiment analysis, text classification and natural language inference. Experimental results demonstrate that our model consistently achieves both better attack performance and higher efficiency than recently proposed baseline methods. We also find our attack model can bring more robustness improvement to the victim model by adversarial training. All the code and data of this paper will be made public.
OpenAttack: An Open-source Textual Adversarial Attack Toolkit
Sep 19, 2020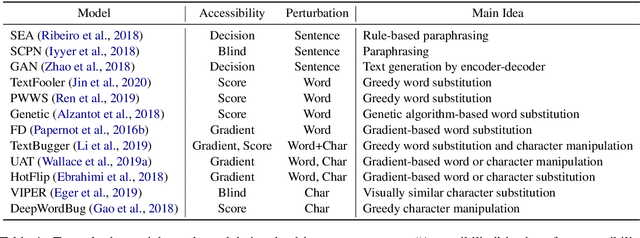
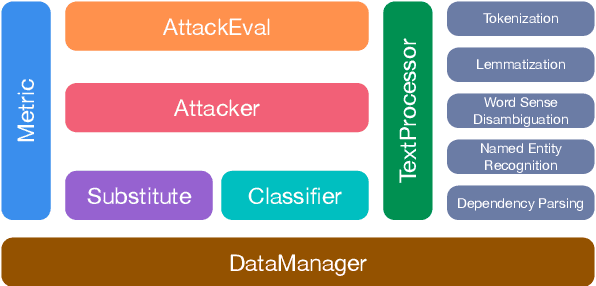
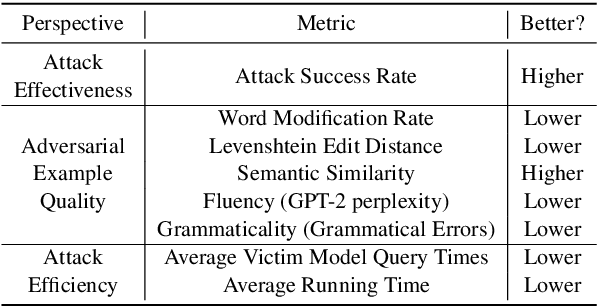
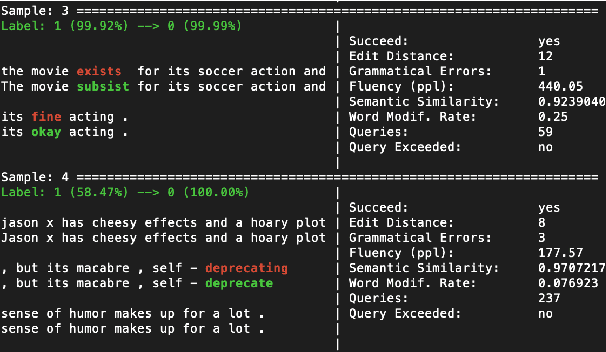
Textual adversarial attacking has received wide and increasing attention in recent years. Various attack models have been proposed, which are enormously distinct and implemented with different programming frameworks and settings. These facts hinder quick utilization and apt comparison of attack models. In this paper, we present an open-source textual adversarial attack toolkit named OpenAttack. It currently builds in 12 typical attack models that cover all the attack types. Its highly inclusive modular design not only supports quick utilization of existing attack models, but also enables great flexibility and extensibility. OpenAttack has broad uses including comparing and evaluating attack models, measuring robustness of a victim model, assisting in developing new attack models, and adversarial training. Source code, built-in models and documentation can be obtained at https://github.com/thunlp/OpenAttack.
Textual Adversarial Attack as Combinatorial Optimization
Nov 10, 2019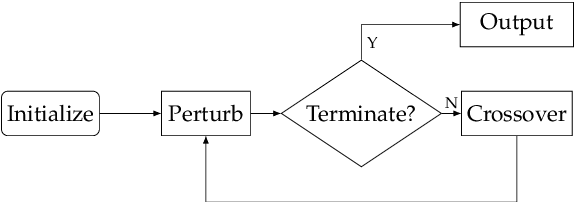
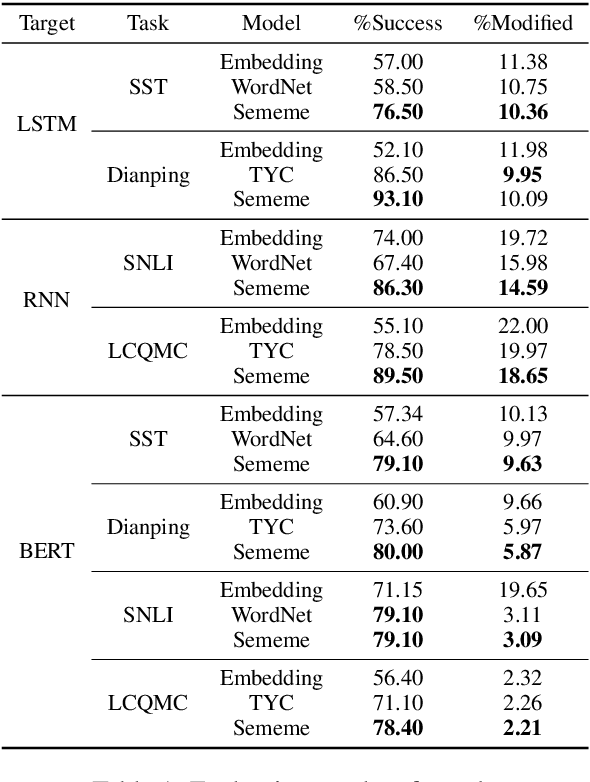
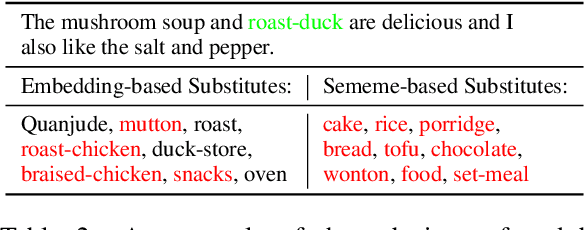
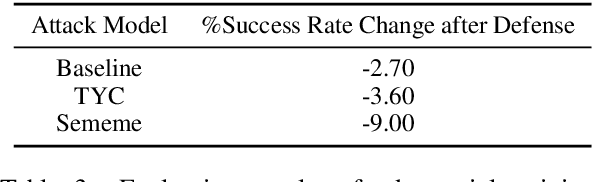
Adversarial attack is carried out to reveal the vulnerability of deep neural networks. Textual adversarial attack is challenging because text is discrete and any perturbation might bring big semantic change. Word substitution is a class of effective textual attack method and has been extensively explored. However, all existing word substitution-based attack methods suffer the problems of bad semantic preservation, insufficient adversarial examples or suboptimal attack results. In this paper, we formalize the word substitution-based attack as a combinatorial optimization problem. We also propose a novel attack model, which comprises a sememe-based word substitution strategy and the particle swarm optimization algorithm, to tackle the existing problems. In experiments, we evaluate our attack model on the sentiment analysis task. Experimental results demonstrate our model achieves higher attack success rates and less modification than the baseline methods. The ablation study also verifies the superiority of the two parts of our model over previous ones.