 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Vision-Language Pretrained Models Learn Primitive Concepts?
Paper and Code
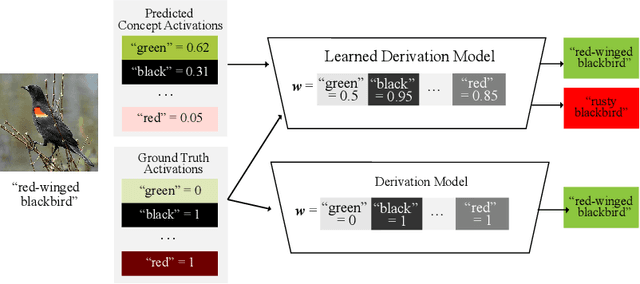
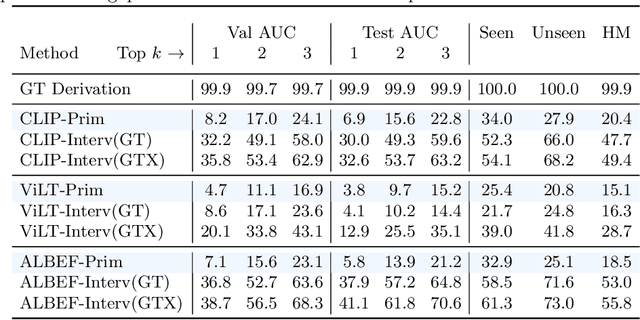
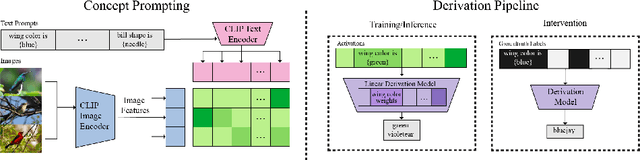
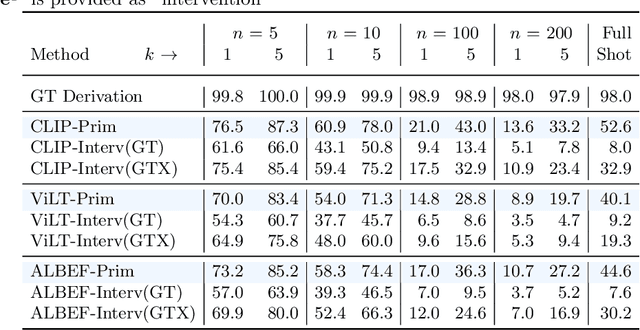
Vision-language pretrained models have achieved impressive performance on multimodal reasoning and zero-shot recognition tasks. Many of these VL models are pretrained on unlabeled image and caption pairs from the internet. In this paper, we study whether the notion of primitive concepts, such as color and shape attributes, emerges automatically from these pretrained VL models. We propose to learn compositional derivations that map primitive concept activations into composite concepts, a task which we demonstrate to be straightforward given true primitive concept annotations. This compositional derivation learning (CompDL) framework allows us to quantitively measure the usefulness and interpretability of the learned derivations, by jointly considering the entire set of candidate primitive concepts. Our study reveals that state-of-the-art VL pretrained models learn primitive concepts that are highly useful as visual descriptors, as demonstrated by their strong performance on fine-grained visual recognition tasks, but those concepts struggle to provide interpretable compositional derivations, which highlights limitations of existing VL models. Code and models will be released.