 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwapNet: Efficient Swapping for DNN Inference on Edge AI Devices Beyond the Memory Budget
Jan 30, 2024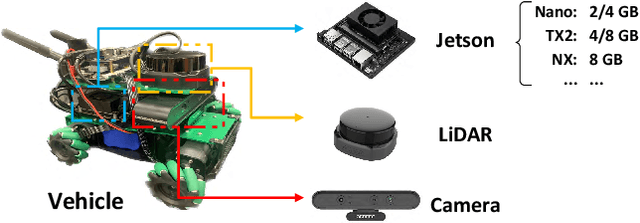
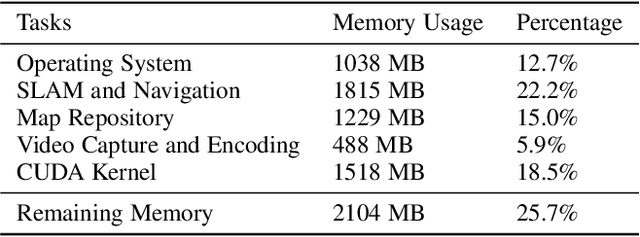
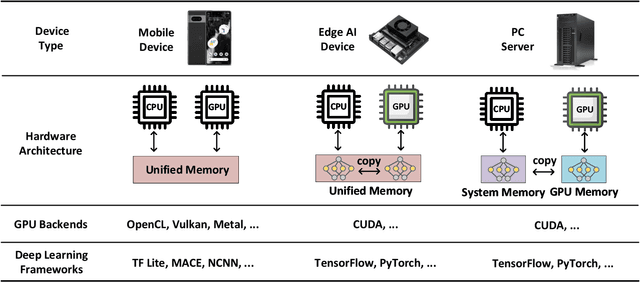
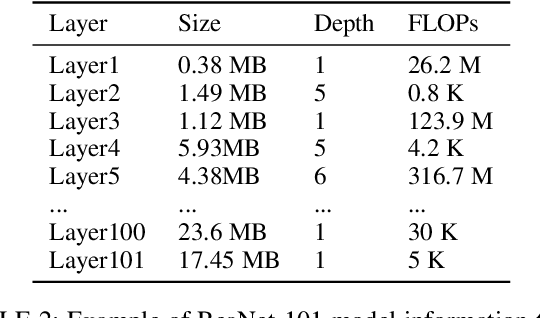
Executing deep neural networks (DNNs) on edge artificial intelligence (AI) devices enables various autonomous mobile computing applications. However, the memory budget of edge AI devices restricts the number and complexity of DNNs allowed in such applications. Existing solutions, such as model compression or cloud offloading, reduce the memory footprint of DNN inference at the cost of decreased model accuracy or autonomy. To avoid these drawbacks, we divide DNN into blocks and swap them in and out in order, such that large DNNs can execute within a small memory budget. Nevertheless, naive swapping on edge AI devices induces significant delays due to the redundant memory operations in the DNN development ecosystem for edge AI devices. To this end, we develop SwapNet, an efficient DNN block swapping middleware for edge AI devices. We systematically eliminate the unnecessary memory operations during block swapping while retaining compatible with the deep learning frameworks, GPU backends, and hardware architectures of edge AI devices. We further showcase the utility of SwapNet via a multi-DNN scheduling scheme. Evaluations on eleven DNN inference tasks in three applications demonstrate that SwapNet achieves almost the same latency as the case with sufficient memory even when DNNs demand 2.32x to 5.81x memory beyond the available budget. The design of SwapNet also provides novel and feasible insights for deploying large language models (LLMs) on edge AI devices in the future.