 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling Deep Learning on Edge Devices
Paper and Code
Oct 06, 2022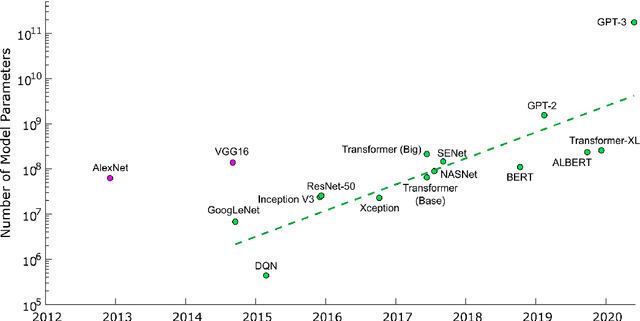

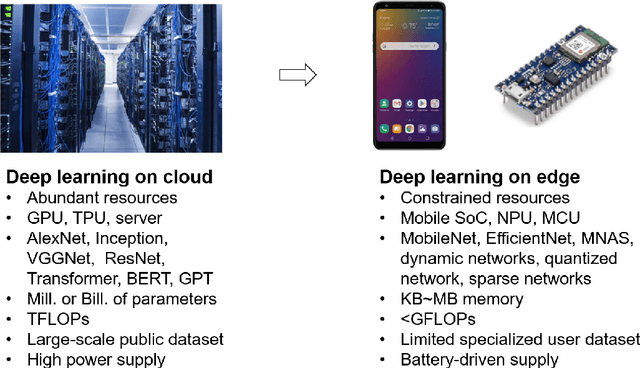

Deep neural networks (DNNs) have succeeded in many different perception tasks, e.g., computer vision, natural language processing, reinforcement learning, etc. The high-performed DNNs heavily rely on intensive resource consumption. For example, training a DNN requires high dynamic memory, a large-scale dataset, and a large number of computations (a long training time); even inference with a DNN also demands a large amount of static storage, computations (a long inference time), and energy. Therefore, state-of-the-art DNNs are often deployed on a cloud server with a large number of super-computers, a high-bandwidth communication bus, a shared storage infrastructure, and a high power supplement. Recently, some new emerging intelligent applications, e.g., AR/VR, mobile assistants, Internet of Things, require us to deploy DNNs on resource-constrained edge devices. Compare to a cloud server, edge devices often have a rather small amount of resources. To deploy DNNs on edge devices, we need to reduce the size of DNNs, i.e., we target a better trade-off between resource consumption and model accuracy. In this dissertation, we studied four edge intelligence scenarios, i.e., Inference on Edge Devices, Adaptation on Edge Devices, Learning on Edge Devices, and Edge-Server Systems, and developed different methodologies to enable deep learning in each scenario. Since current DNNs are often over-parameterized, our goal is to find and reduce the redundancy of the DNNs in each scenario.