 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Rank Robust Subspace Tensor Clustering for Metro Passenger Flow Modeling
Apr 05, 2024Tensor clustering has become an important topic, specifically in spatio-temporal modeling, due to its ability to cluster spatial modes (e.g., stations or road segments) and temporal modes (e.g., time of the day or day of the week). Our motivating example is from subway passenger flow modeling, where similarities between stations are commonly found. However, the challenges lie in the innate high-dimensionality of tensors and also the potential existence of anomalies. This is because the three tasks, i.e., dimension reduction, clustering, and anomaly decomposition, are inter-correlated to each other, and treating them in a separate manner will render a suboptimal performance. Thus, in this work, we design a tensor-based subspace clustering and anomaly decomposition technique for simultaneously outlier-robust dimension reduction and clustering for high-dimensional tensors. To achieve this, a novel low-rank robust subspace clustering decomposition model is proposed by combining Tucker decomposition, sparse anomaly decomposition, and subspace clustering. An effective algorithm based on Block Coordinate Descent is proposed to update the parameters. Prudent experiments prove the effectiveness of the proposed framework via the simulation study, with a gain of +25% clustering accuracy than benchmark methods in a hard case. The interrelations of the three tasks are also analyzed via ablation studies, validating the interrelation assumption. Moreover, a case study in the station clustering based on real passenger flow data is conducted, with quite valuable insights discovered.
Personalized Tucker Decomposition: Modeling Commonality and Peculiarity on Tensor Data
Sep 07, 2023We propose personalized Tucker decomposition (perTucker) to address the limitations of traditional tensor decomposition methods in capturing heterogeneity across different datasets. perTucker decomposes tensor data into shared global components and personalized local components. We introduce a mode orthogonality assumption and develop a proximal gradient regularized block coordinate descent algorithm that is guaranteed to converge to a stationary point. By learning unique and common representations across datasets, we demonstrate perTucker's effectiveness in anomaly detection, client classification, and clustering through a simulation study and two case studies on solar flare detection and tonnage signal classification.
Adaptive Partially-Observed Sequential Change Detection and Isolation
Aug 25, 2022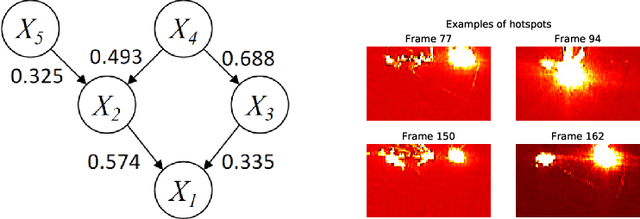
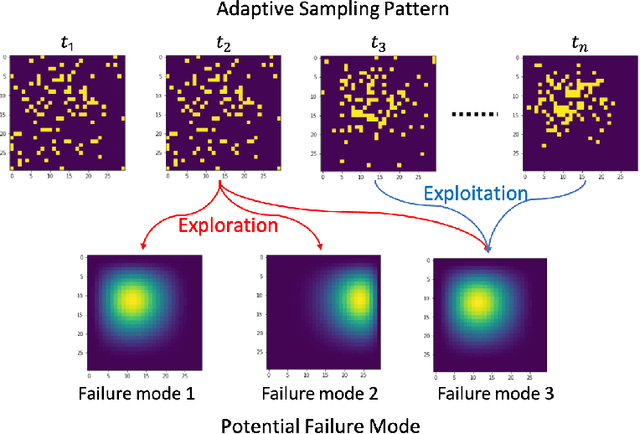
High-dimensional data has become popular due to the easy accessibility of sensors in modern industrial applications. However, one specific challenge is that it is often not easy to obtain complete measurements due to limited sensing powers and resource constraints. Furthermore, distinct failure patterns may exist in the systems, and it is necessary to identify the true failure pattern. This work focuses on the online adaptive monitoring of high-dimensional data in resource-constrained environments with multiple potential failure modes. To achieve this, we propose to apply the Shiryaev-Roberts procedure on the failure mode level and utilize the multi-arm bandit to balance the exploration and exploitation. We further discuss the theoretical property of the proposed algorithm to show that the proposed method can correctly isolate the failure mode. Finally, extensive simulations and two case studies demonstrate that the change point detection performance and the failure mode isolation accuracy can be greatly improved.
Adaptive Resources Allocation CUSUM for Binomial Count Data Monitoring with Application to COVID-19 Hotspot Detection
Aug 17, 2022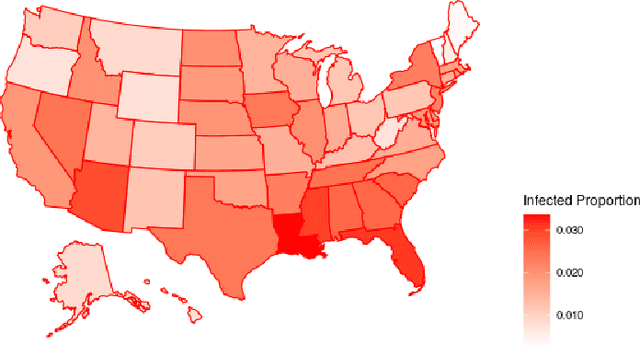
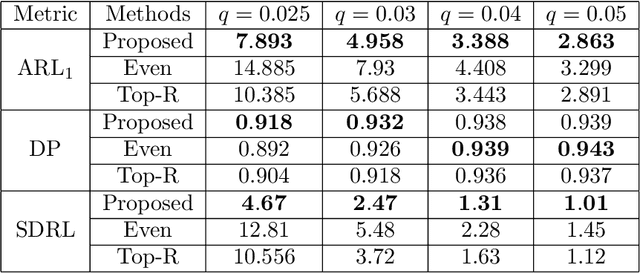
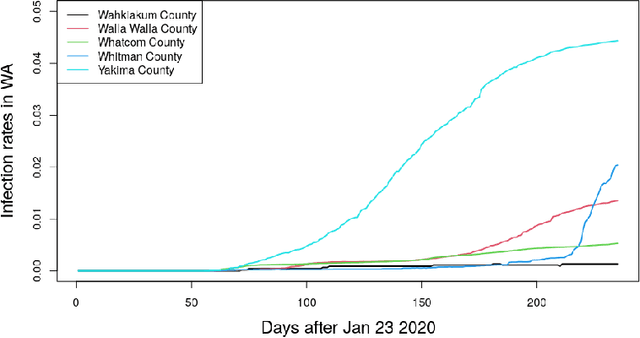
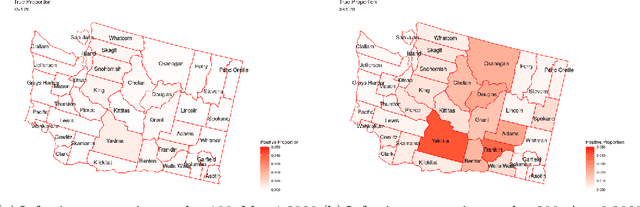
In this paper, we present an efficient statistical method (denoted as "Adaptive Resources Allocation CUSUM") to robustly and efficiently detect the hotspot with limited sampling resources. Our main idea is to combine the multi-arm bandit (MAB) and change-point detection methods to balance the exploration and exploitation of resource allocation for hotspot detection. Further, a Bayesian weighted update is used to update the posterior distribution of the infection rate. Then, the upper confidence bound (UCB) is used for resource allocation and planning. Finally, CUSUM monitoring statistics to detect the change point as well as the change location. For performance evaluation, we compare the performance of the proposed method with several benchmark methods in the literature and showed the proposed algorithm is able to achieve a lower detection delay and higher detection precision. Finally, this method is applied to hotspot detection in a real case study of county-level daily positive COVID-19 cases in Washington State WA) and demonstrates the effectiveness with very limited distributed samples.