 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBelt-Finger: An Affordable Soft Belt-Driven Gripper for Dexterous In-Hand Manipulation
Jun 18, 2026Parallel-jaw grippers are the default manipulator choice in robotics because they are simple, robust, and inexpensive. Their limited in-hand mobility, however, often forces large arm motions and restricts dexterous manipulation in confined workspaces. We present a parallel-gripper upgrade: a double-soft-belt-based finger module that preserves standard opening/closing while adding three in-hand degrees of freedom (DoF): translation, pitch, and roll. The mechanism is deliberately kept simple and engineered for inexpensive manufacturing and straightforward integration, preserving the reliability and precise control of traditional parallel grippers while greatly broadening the range of manipulation capabilities. To demonstrate the utility of the added DoFs, we integrate the gripper in two control pipelines. First, we adapt a model predictive controller for in-hand manipulation of known objects. Second, we introduce a lightweight teleoperation interface that enables simultaneous control of the robot arm and gripper (10 DoFs total) with minimal hardware. Across a suite of challenging manipulation tasks executed via teleoperation, MPC, and trained policies, the proposed gripper consistently improves dexterity and task feasibility compared to a conventional parallel gripper
GaussianPile: A Unified Sparse Gaussian Splatting Framework for Slice-based Volumetric Reconstruction
Mar 21, 2026Slice-based volumetric imaging is widely applied and it demands representations that compress aggressively while preserving internal structure for analysis. We introduce GaussianPile, unifying 3D Gaussian splatting with an imaging system-aware focus model to address this challenge. Our proposed method introduces three key innovations: (i) a slice-aware piling strategy that positions anisotropic 3D Gaussians to model through-slice contributions, (ii) a differentiable projection operator that encodes the finite-thickness point spread function of the imaging acquisition system, and (iii) a compact encoding and joint optimization pipeline that simultaneously reconstructs and compresses the Gaussian sets. Our CUDA-based design retains the compression and real-time rendering efficiency of Gaussian primitives while preserving high-frequency internal volumetric detail. Experiments on microscopy and ultrasound datasets demonstrate that our method reduces storage and reconstruction cost, sustains diagnostic fidelity, and enables fast 2D visualization, along with 3D voxelization. In practice, it delivers high-quality results in as few as 3 minutes, up to 11x faster than NeRF-based approaches, and achieves consistent 16x compression over voxel grids, offering a practical path to deployable compression and exploration of slice-based volumetric datasets.
FreqCycle: A Multi-Scale Time-Frequency Analysis Method for Time Series Forecasting
Mar 10, 2026Mining time-frequency features is critical for time series forecasting. Existing research has predominantly focused on modeling low-frequency patterns, where most time series energy is concentrated. The overlooking of mid to high frequency continues to limit further performance gains in deep learning models. We propose FreqCycle, a novel framework integrating: (i) a Filter-Enhanced Cycle Forecasting (FECF) module to extract low-frequency features by explicitly learning shared periodic patterns in the time domain, and (ii) a Segmented Frequency-domain Pattern Learning (SFPL) module to enhance mid to high frequency energy proportion via learnable filters and adaptive weighting. Furthermore, time series data often exhibit coupled multi-periodicity, such as intertwined weekly and daily cycles. To address coupled multi-periodicity as well as long lookback window challenges, we extend FreqCycle hierarchically into MFreqCycle, which decouples nested periodic features through cross-scale interactions. Extensive experiments on seven diverse domain benchmarks demonstrate that FreqCycle achieves state-of-the-art accuracy while maintaining faster inference speeds, striking an optimal balance between performance and efficiency.
From Scalar Rewards to Potential Trends: Shaping Potential Landscapes for Model-Based Reinforcement Learning
Feb 03, 2026Model-based reinforcement learning (MBRL) achieves high sample efficiency by simulating future trajectories with learned dynamics and reward models. However, its effectiveness is severely compromised in sparse reward settings. The core limitation lies in the standard paradigm of regressing ground-truth scalar rewards: in sparse environments, this yields a flat, gradient-free landscape that fails to provide directional guidance for planning. To address this challenge, we propose Shaping Landscapes with Optimistic Potential Estimates (SLOPE), a novel framework that shifts reward modeling from predicting scalars to constructing informative potential landscapes. SLOPE employs optimistic distributional regression to estimate high-confidence upper bounds, which amplifies rare success signals and ensures sufficient exploration gradients. Evaluations on 30+ tasks across 5 benchmarks demonstrate that SLOPE consistently outperforms leading baselines in fully sparse, semi-sparse, and dense rewards.
The Role of Tactile Sensing for Learning Reach and Grasp
Feb 27, 2025Stable and robust robotic grasping is essential for current and future robot applications. In recent works, the use of large datasets and supervised learning has enhanced speed and precision in antipodal grasping. However, these methods struggle with perception and calibration errors due to large planning horizons. To obtain more robust and reactive grasping motions, leveraging reinforcement learning combined with tactile sensing is a promising direction. Yet, there is no systematic evaluation of how the complexity of force-based tactile sensing affects the learning behavior for grasping tasks. This paper compares various tactile and environmental setups using two model-free reinforcement learning approaches for antipodal grasping. Our findings suggest that under imperfect visual perception, various tactile features improve learning outcomes, while complex tactile inputs complicate training.
Hierarchical Sparse Bayesian Multitask Model with Scalable Inference for Microbiome Analysis
Feb 04, 2025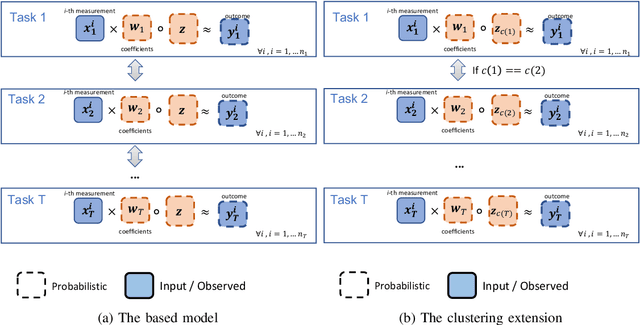
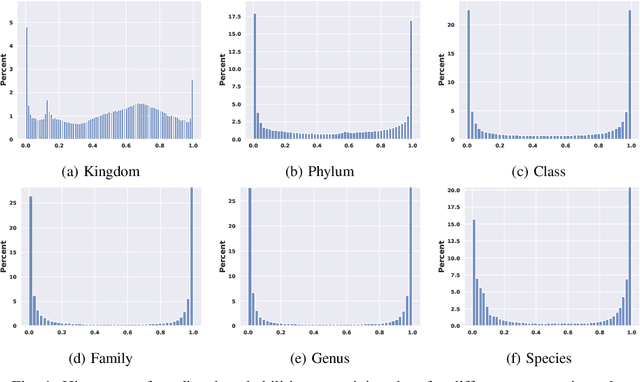
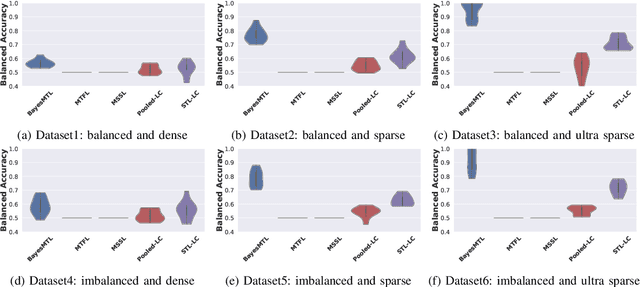
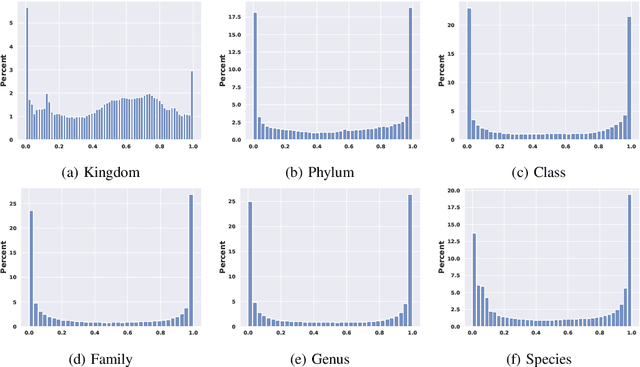
This paper proposes a hierarchical Bayesian multitask learning model that is applicable to the general multi-task binary classification learning problem where the model assumes a shared sparsity structure across different tasks. We derive a computationally efficient inference algorithm based on variational inference to approximate the posterior distribution. We demonstrate the potential of the new approach on various synthetic datasets and for predicting human health status based on microbiome profile. Our analysis incorporates data pooled from multiple microbiome studies, along with a comprehensive comparison with other benchmark methods. Results in synthetic datasets show that the proposed approach has superior support recovery property when the underlying regression coefficients share a common sparsity structure across different tasks. Our experiments on microbiome classification demonstrate the utility of the method in extracting informative taxa while providing well-calibrated predictions with uncertainty quantification and achieving competitive performance in terms of prediction metrics. Notably, despite the heterogeneity of the pooled datasets (e.g., different experimental objectives, laboratory setups, sequencing equipment, patient demographics), our method delivers robust results.
CT-ADE: An Evaluation Benchmark for Adverse Drug Event Prediction from Clinical Trial Results
Apr 19, 2024Adverse drug events (ADEs) significantly impact clinical research and public health, contributing to failures in clinical trials and leading to increased healthcare costs. The accurate prediction and management of ADEs are crucial for improving the development of safer, more effective medications, and enhancing patient outcomes. To support this effort, we introduce CT-ADE, a novel dataset compiled to enhance the predictive modeling of ADEs. Encompassing over 12,000 instances extracted from clinical trial results, the CT-ADE dataset integrates drug, patient population, and contextual information for multilabel ADE classification tasks in monopharmacy treatments, providing a comprehensive resource for developing advanced predictive models. To mirror the complex nature of ADEs, annotations are standardized at the system organ class level of the Medical Dictionary for Regulatory Activities (MedDRA) ontology. Preliminary analyses using baseline models have demonstrated promising results, achieving 73.33% F1 score and 81.54% balanced accuracy, highlighting CT-ADE's potential to advance ADE prediction. CT-ADE provides an essential tool for researchers aiming to leverage the power of artificial intelligence and machine learning to enhance patient safety and minimize the impact of ADEs on pharmaceutical research and development. Researchers interested in using the CT-ADE dataset can find all necessary resources at https://github.com/xxxx/xxxx.
Purify++: Improving Diffusion-Purification with Advanced Diffusion Models and Control of Randomness
Oct 28, 2023
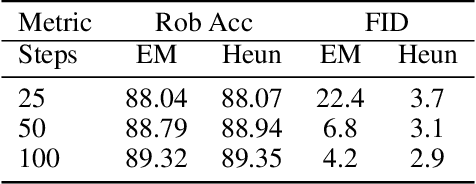
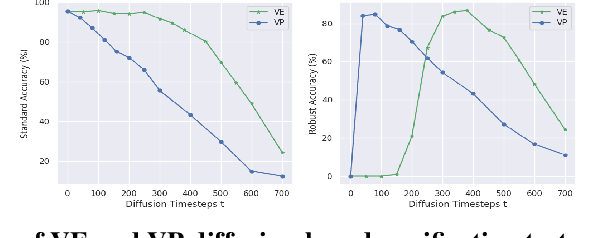

Adversarial attacks can mislead neural network classifiers. The defense against adversarial attacks is important for AI safety. Adversarial purification is a family of approaches that defend adversarial attacks with suitable pre-processing. Diffusion models have been shown to be effective for adversarial purification. Despite their success, many aspects of diffusion purification still remain unexplored. In this paper, we investigate and improve upon three limiting designs of diffusion purification: the use of an improved diffusion model, advanced numerical simulation techniques, and optimal control of randomness. Based on our findings, we propose Purify++, a new diffusion purification algorithm that is now the state-of-the-art purification method against several adversarial attacks. Our work presents a systematic exploration of the limits of diffusion purification methods.
Enhancing Adversarial Robustness via Score-Based Optimization
Jul 10, 2023



Adversarial attacks have the potential to mislead deep neural network classifiers by introducing slight perturbations. Developing algorithms that can mitigate the effects of these attacks is crucial for ensuring the safe use of artificial intelligence. Recent studies have suggested that score-based diffusion models are effective in adversarial defenses. However, existing diffusion-based defenses rely on the sequential simulation of the reversed stochastic differential equations of diffusion models, which are computationally inefficient and yield suboptimal results. In this paper, we introduce a novel adversarial defense scheme named ScoreOpt, which optimizes adversarial samples at test-time, towards original clean data in the direction guided by score-based priors. We conduct comprehensive experiments on multiple datasets, including CIFAR10, CIFAR100 and ImageNet. Our experimental results demonstrate that our approach outperforms existing adversarial defenses in terms of both robustness performance and inference speed.
Entropy-based Training Methods for Scalable Neural Implicit Sampler
Jun 08, 2023Efficiently sampling from un-normalized target distributions is a fundamental problem in scientific computing and machine learning. Traditional approaches like Markov Chain Monte Carlo (MCMC) guarantee asymptotically unbiased samples from such distributions but suffer from computational inefficiency, particularly when dealing with high-dimensional targets, as they require numerous iterations to generate a batch of samples. In this paper, we propose an efficient and scalable neural implicit sampler that overcomes these limitations. Our sampler can generate large batches of samples with low computational costs by leveraging a neural transformation that directly maps easily sampled latent vectors to target samples without the need for iterative procedures. To train the neural implicit sampler, we introduce two novel methods: the KL training method and the Fisher training method. The former minimizes the Kullback-Leibler divergence, while the latter minimizes the Fisher divergence. By employing these training methods, we effectively optimize the neural implicit sampler to capture the desired target distribution. To demonstrate the effectiveness, efficiency, and scalability of our proposed samplers, we evaluate them on three sampling benchmarks with different scales. These benchmarks include sampling from 2D targets, Bayesian inference, and sampling from high-dimensional energy-based models (EBMs). Notably, in the experiment involving high-dimensional EBMs, our sampler produces samples that are comparable to those generated by MCMC-based methods while being more than 100 times more efficient, showcasing the efficiency of our neural sampler. We believe that the theoretical and empirical contributions presented in this work will stimulate further research on developing efficient samplers for various applications beyond the ones explored in this study.