 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDS4DH at TREC Health Misinformation 2021: Multi-Dimensional Ranking Models with Transfer Learning and Rank Fusion
Feb 14, 2022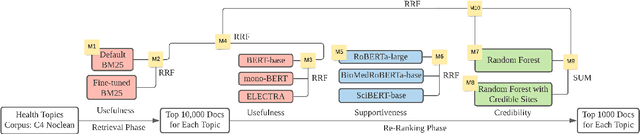

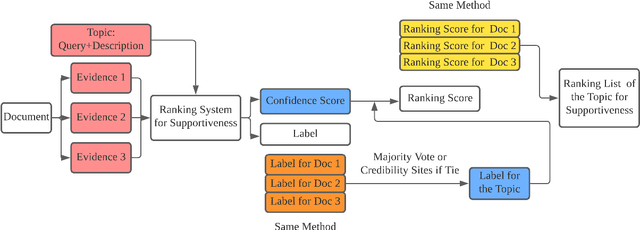
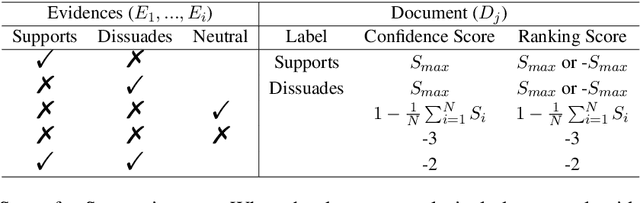
This paper describes the work of the Data Science for Digital Health (DS4DH) group at the TREC Health Misinformation Track 2021. The TREC Health Misinformation track focused on the development of retrieval methods that provide relevant, correct and credible information for health related searches on the Web. In our methodology, we used a two-step ranking approach that includes i) a standard retrieval phase, based on BM25 model, and ii) a re-ranking phase, with a pipeline of models focused on the usefulness, supportiveness and credibility dimensions of the retrieved documents. To estimate the usefulness, we classified the initial rank list using pre-trained language models based on the transformers architecture fine-tuned on the MS MARCO corpus. To assess the supportiveness, we utilized BERT-based models fine-tuned on scientific and Wikipedia corpora. Finally, to evaluate the credibility of the documents, we employed a random forest model trained on the Microsoft Credibility dataset combined with a list of credible sites. The resulting ranked lists were then combined using the Reciprocal Rank Fusion algorithm to obtain the final list of useful, supporting and credible documents. Our approach achieved competitive results, being top-2 in the compatibility measurement for the automatic runs. Our findings suggest that integrating automatic ranking models created for each information quality dimension with transfer learning can increase the effectiveness of health-related information retrieval.