 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePurify++: Improving Diffusion-Purification with Advanced Diffusion Models and Control of Randomness
Paper and Code

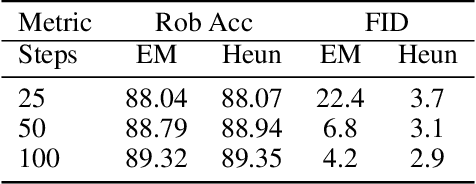
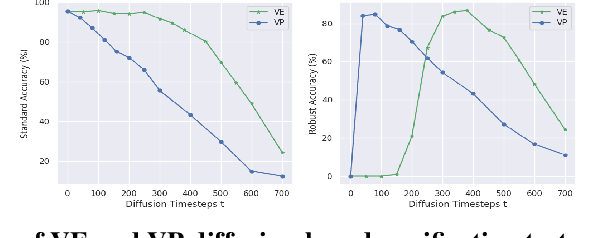

Adversarial attacks can mislead neural network classifiers. The defense against adversarial attacks is important for AI safety. Adversarial purification is a family of approaches that defend adversarial attacks with suitable pre-processing. Diffusion models have been shown to be effective for adversarial purification. Despite their success, many aspects of diffusion purification still remain unexplored. In this paper, we investigate and improve upon three limiting designs of diffusion purification: the use of an improved diffusion model, advanced numerical simulation techniques, and optimal control of randomness. Based on our findings, we propose Purify++, a new diffusion purification algorithm that is now the state-of-the-art purification method against several adversarial attacks. Our work presents a systematic exploration of the limits of diffusion purification methods.