 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Choice of Knowledge Base in Automated Claim Checking
Paper and Code

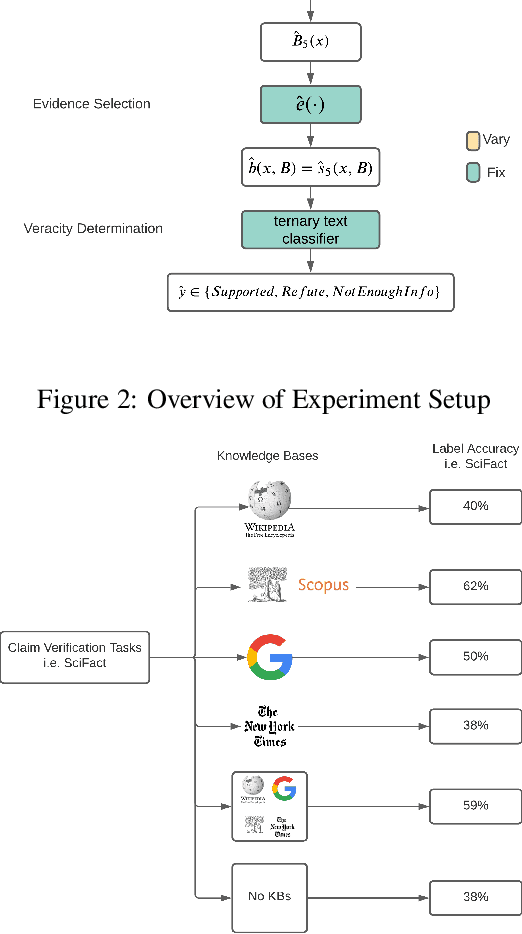
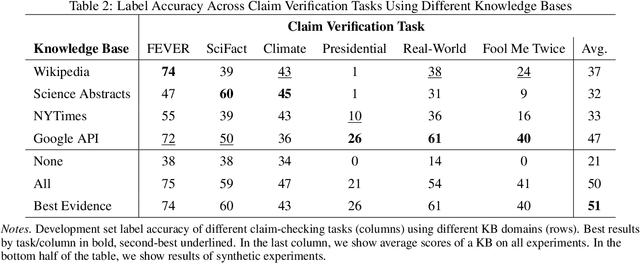
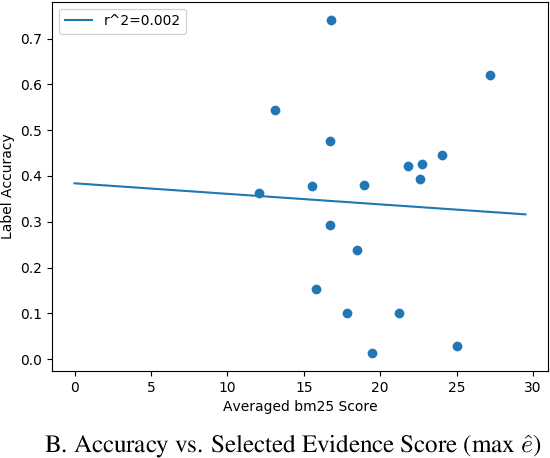
Automated claim checking is the task of determining the veracity of a claim given evidence found in a knowledge base of trustworthy facts. While previous work has taken the knowledge base as given and optimized the claim-checking pipeline, we take the opposite approach - taking the pipeline as given, we explore the choice of knowledge base. Our first insight is that a claim-checking pipeline can be transferred to a new domain of claims with access to a knowledge base from the new domain. Second, we do not find a "universally best" knowledge base - higher domain overlap of a task dataset and a knowledge base tends to produce better label accuracy. Third, combining multiple knowledge bases does not tend to improve performance beyond using the closest-domain knowledge base. Finally, we show that the claim-checking pipeline's confidence score for selecting evidence can be used to assess whether a knowledge base will perform well for a new set of claims, even in the absence of ground-truth labels.