 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWatermarking Graph Neural Networks via Explanations for Ownership Protection
Jan 09, 2025Graph Neural Networks (GNNs) are the mainstream method to learn pervasive graph data and are widely deployed in industry, making their intellectual property valuable. However, protecting GNNs from unauthorized use remains a challenge. Watermarking, which embeds ownership information into a model, is a potential solution. However, existing watermarking methods have two key limitations: First, almost all of them focus on non-graph data, with watermarking GNNs for complex graph data largely unexplored. Second, the de facto backdoor-based watermarking methods pollute training data and induce ownership ambiguity through intentional misclassification. Our explanation-based watermarking inherits the strengths of backdoor-based methods (e.g., robust to watermark removal attacks), but avoids data pollution and eliminates intentional misclassification. In particular, our method learns to embed the watermark in GNN explanations such that this unique watermark is statistically distinct from other potential solutions, and ownership claims must show statistical significance to be verified. We theoretically prove that, even with full knowledge of our method, locating the watermark is an NP-hard problem. Empirically, our method manifests robustness to removal attacks like fine-tuning and pruning. By addressing these challenges, our approach marks a significant advancement in protecting GNN intellectual property.
Efficient and Robust Continual Graph Learning for Graph Classification in Biology
Nov 18, 2024



Graph classification is essential for understanding complex biological systems, where molecular structures and interactions are naturally represented as graphs. Traditional graph neural networks (GNNs) perform well on static tasks but struggle in dynamic settings due to catastrophic forgetting. We present Perturbed and Sparsified Continual Graph Learning (PSCGL), a robust and efficient continual graph learning framework for graph data classification, specifically targeting biological datasets. We introduce a perturbed sampling strategy to identify critical data points that contribute to model learning and a motif-based graph sparsification technique to reduce storage needs while maintaining performance. Additionally, our PSCGL framework inherently defends against graph backdoor attacks, which is crucial for applications in sensitive biological contexts. Extensive experiments on biological datasets demonstrate that PSCGL not only retains knowledge across tasks but also enhances the efficiency and robustness of graph classification models in biology.
Securing GNNs: Explanation-Based Identification of Backdoored Training Graphs
Mar 26, 2024
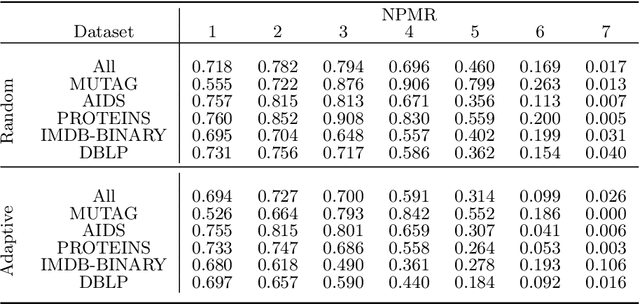


Graph Neural Networks (GNNs) have gained popularity in numerous domains, yet they are vulnerable to backdoor attacks that can compromise their performance and ethical application. The detection of these attacks is crucial for maintaining the reliability and security of GNN classification tasks, but effective detection techniques are lacking. Following an initial investigation, we observed that while graph-level explanations can offer limited insights, their effectiveness in detecting backdoor triggers is inconsistent and incomplete. To bridge this gap, we extract and transform secondary outputs of GNN explanation mechanisms, designing seven novel metrics that more effectively detect backdoor attacks. Additionally, we develop an adaptive attack to rigorously evaluate our approach. We test our method on multiple benchmark datasets and examine its efficacy against various attack models. Our results show that our method can achieve high detection performance, marking a significant advancement in safeguarding GNNs against backdoor attacks.