 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecuring GNNs: Explanation-Based Identification of Backdoored Training Graphs
Paper and Code
Mar 26, 2024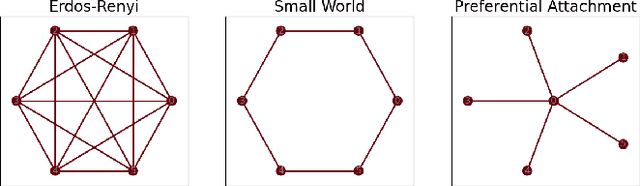
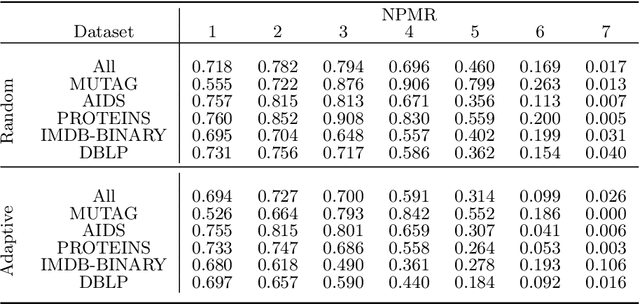


Graph Neural Networks (GNNs) have gained popularity in numerous domains, yet they are vulnerable to backdoor attacks that can compromise their performance and ethical application. The detection of these attacks is crucial for maintaining the reliability and security of GNN classification tasks, but effective detection techniques are lacking. Following an initial investigation, we observed that while graph-level explanations can offer limited insights, their effectiveness in detecting backdoor triggers is inconsistent and incomplete. To bridge this gap, we extract and transform secondary outputs of GNN explanation mechanisms, designing seven novel metrics that more effectively detect backdoor attacks. Additionally, we develop an adaptive attack to rigorously evaluate our approach. We test our method on multiple benchmark datasets and examine its efficacy against various attack models. Our results show that our method can achieve high detection performance, marking a significant advancement in safeguarding GNNs against backdoor attacks.