 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Local Structure for Improving Model Explanations: An Information Propagation Approach
Sep 24, 2024

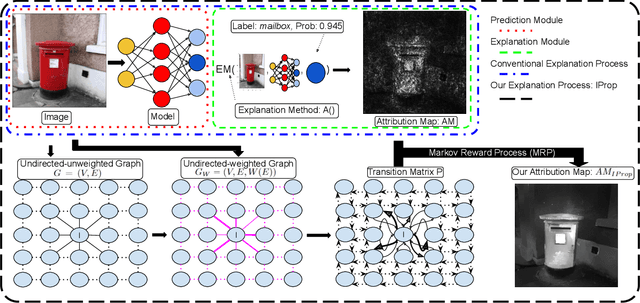
Numerous explanation methods have been recently developed to interpret the decisions made by deep neural network (DNN) models. For image classifiers, these methods typically provide an attribution score to each pixel in the image to quantify its contribution to the prediction. However, most of these explanation methods appropriate attribution scores to pixels independently, even though both humans and DNNs make decisions by analyzing a set of closely related pixels simultaneously. Hence, the attribution score of a pixel should be evaluated jointly by considering itself and its structurally-similar pixels. We propose a method called IProp, which models each pixel's individual attribution score as a source of explanatory information and explains the image prediction through the dynamic propagation of information across all pixels. To formulate the information propagation, IProp adopts the Markov Reward Process, which guarantees convergence, and the final status indicates the desired pixels' attribution scores. Furthermore, IProp is compatible with any existing attribution-based explanation method. Extensive experiments on various explanation methods and DNN models verify that IProp significantly improves them on a variety of interpretability metrics.
IDGI: A Framework to Eliminate Explanation Noise from Integrated Gradients
Mar 24, 2023



Integrated Gradients (IG) as well as its variants are well-known techniques for interpreting the decisions of deep neural networks. While IG-based approaches attain state-of-the-art performance, they often integrate noise into their explanation saliency maps, which reduce their interpretability. To minimize the noise, we examine the source of the noise analytically and propose a new approach to reduce the explanation noise based on our analytical findings. We propose the Important Direction Gradient Integration (IDGI) framework, which can be easily incorporated into any IG-based method that uses the Reimann Integration for integrated gradient computation. Extensive experiments with three IG-based methods show that IDGI improves them drastically on numerous interpretability metrics.