 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMDocBench: Benchmarking Large Vision-Language Models for Fine-Grained Visual Document Understanding
Paper and Code
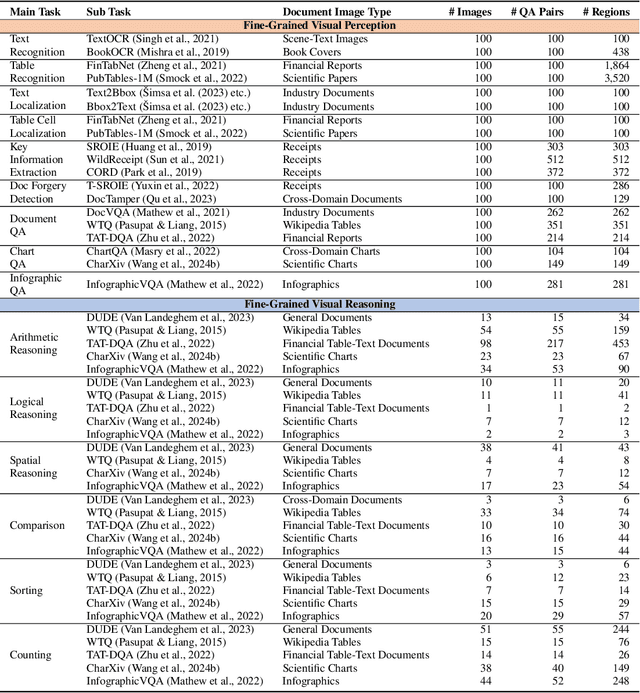

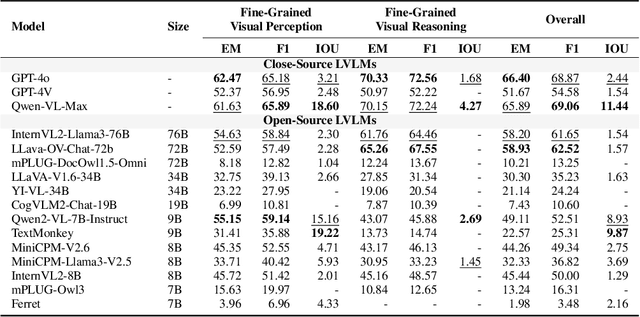
Large Vision-Language Models (LVLMs) have achieved remarkable performance in many vision-language tasks, yet their capabilities in fine-grained visual understanding remain insufficiently evaluated. Existing benchmarks either contain limited fine-grained evaluation samples that are mixed with other data, or are confined to object-level assessments in natural images. To holistically assess LVLMs' fine-grained visual understanding capabilities, we propose using document images with multi-granularity and multi-modal information to supplement natural images. In this light, we construct MMDocBench, a benchmark with various OCR-free document understanding tasks for the evaluation of fine-grained visual perception and reasoning abilities. MMDocBench defines 15 main tasks with 4,338 QA pairs and 11,353 supporting regions, covering various document images such as research papers, receipts, financial reports, Wikipedia tables, charts, and infographics. Based on MMDocBench, we conduct extensive experiments using 13 open-source and 3 proprietary advanced LVLMs, assessing their strengths and weaknesses across different tasks and document image types. The benchmark, task instructions, and evaluation code will be made publicly available.