 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMDocBench: Benchmarking Large Vision-Language Models for Fine-Grained Visual Document Understanding
Oct 25, 2024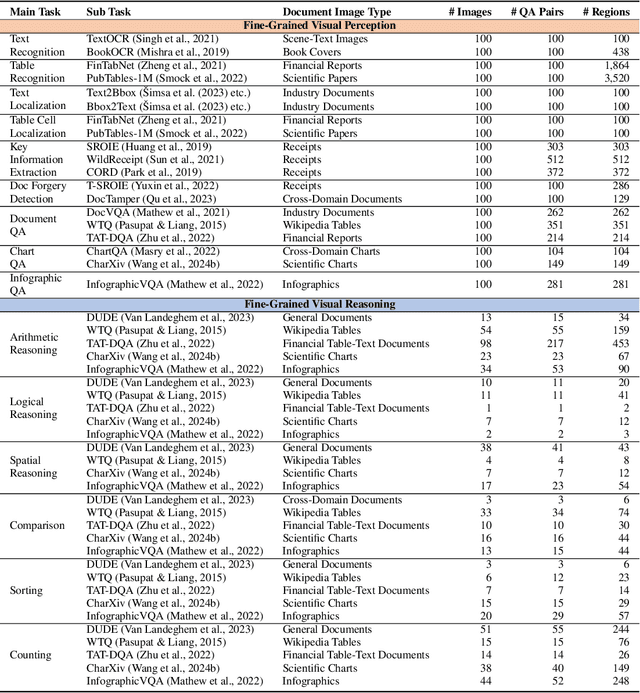

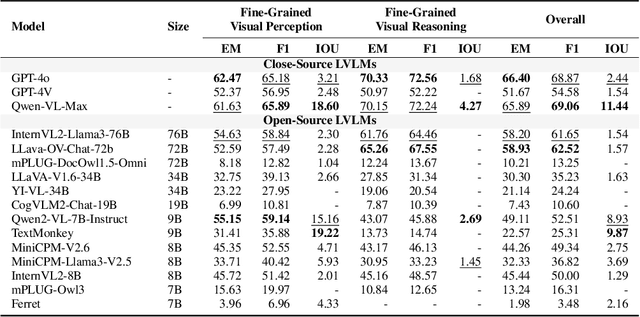
Large Vision-Language Models (LVLMs) have achieved remarkable performance in many vision-language tasks, yet their capabilities in fine-grained visual understanding remain insufficiently evaluated. Existing benchmarks either contain limited fine-grained evaluation samples that are mixed with other data, or are confined to object-level assessments in natural images. To holistically assess LVLMs' fine-grained visual understanding capabilities, we propose using document images with multi-granularity and multi-modal information to supplement natural images. In this light, we construct MMDocBench, a benchmark with various OCR-free document understanding tasks for the evaluation of fine-grained visual perception and reasoning abilities. MMDocBench defines 15 main tasks with 4,338 QA pairs and 11,353 supporting regions, covering various document images such as research papers, receipts, financial reports, Wikipedia tables, charts, and infographics. Based on MMDocBench, we conduct extensive experiments using 13 open-source and 3 proprietary advanced LVLMs, assessing their strengths and weaknesses across different tasks and document image types. The benchmark, task instructions, and evaluation code will be made publicly available.
Can I Trust Your Answer? Visually Grounded Video Question Answering
Sep 04, 2023We study visually grounded VideoQA in response to the emerging trends of utilizing pretraining techniques for video-language understanding. Specifically, by forcing vision-language models (VLMs) to answer questions and simultaneously provide visual evidence, we seek to ascertain the extent to which the predictions of such techniques are genuinely anchored in relevant video content, versus spurious correlations from language or irrelevant visual context. Towards this, we construct NExT-GQA -- an extension of NExT-QA with 10.5$K$ temporal grounding (or location) labels tied to the original QA pairs. With NExT-GQA, we scrutinize a variety of state-of-the-art VLMs. Through post-hoc attention analysis, we find that these models are weak in substantiating the answers despite their strong QA performance. This exposes a severe limitation of these models in making reliable predictions. As a remedy, we further explore and suggest a video grounding mechanism via Gaussian mask optimization and cross-modal learning. Experiments with different backbones demonstrate that this grounding mechanism improves both video grounding and QA. Our dataset and code are released. With these efforts, we aim to push towards the reliability of deploying VLMs in VQA systems.
RDU: A Region-based Approach to Form-style Document Understanding
Jun 14, 2022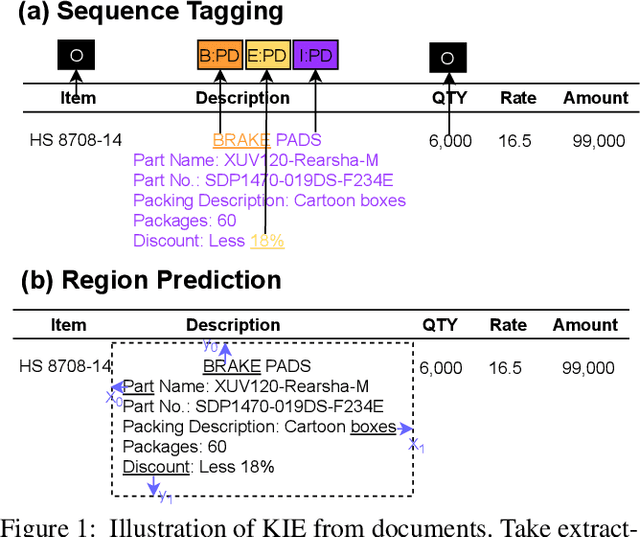
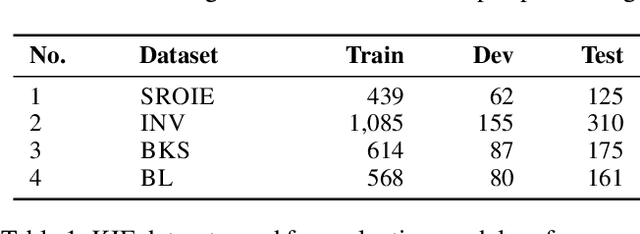
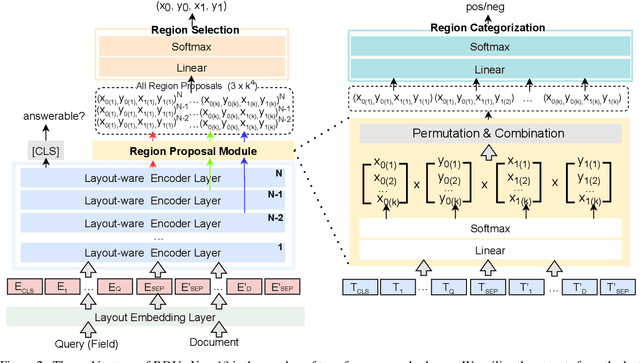
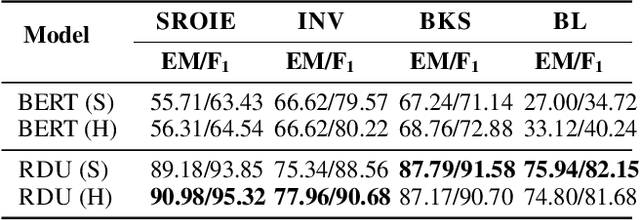
Key Information Extraction (KIE) is aimed at extracting structured information (e.g. key-value pairs) from form-style documents (e.g. invoices), which makes an important step towards intelligent document understanding. Previous approaches generally tackle KIE by sequence tagging, which faces difficulty to process non-flatten sequences, especially for table-text mixed documents. These approaches also suffer from the trouble of pre-defining a fixed set of labels for each type of documents, as well as the label imbalance issue. In this work, we assume Optical Character Recognition (OCR) has been applied to input documents, and reformulate the KIE task as a region prediction problem in the two-dimensional (2D) space given a target field. Following this new setup, we develop a new KIE model named Region-based Document Understanding (RDU) that takes as input the text content and corresponding coordinates of a document, and tries to predict the result by localizing a bounding-box-like region. Our RDU first applies a layout-aware BERT equipped with a soft layout attention masking and bias mechanism to incorporate layout information into the representations. Then, a list of candidate regions is generated from the representations via a Region Proposal Module inspired by computer vision models widely applied for object detection. Finally, a Region Categorization Module and a Region Selection Module are adopted to judge whether a proposed region is valid and select the one with the largest probability from all proposed regions respectively. Experiments on four types of form-style documents show that our proposed method can achieve impressive results. In addition, our RDU model can be trained with different document types seamlessly, which is especially helpful over low-resource documents.