 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRDU: A Region-based Approach to Form-style Document Understanding
Paper and Code
Jun 14, 2022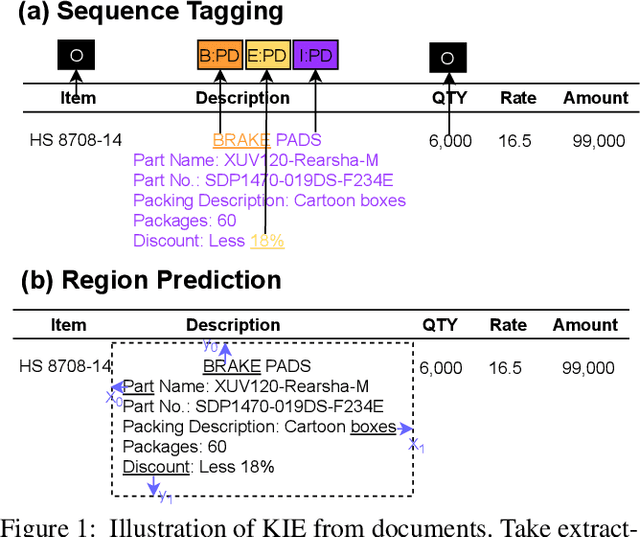
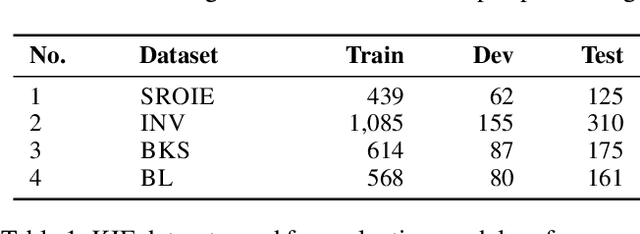
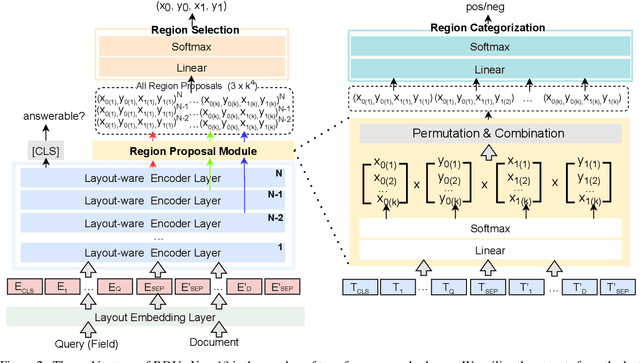
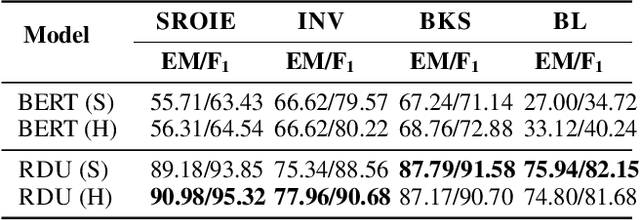
Key Information Extraction (KIE) is aimed at extracting structured information (e.g. key-value pairs) from form-style documents (e.g. invoices), which makes an important step towards intelligent document understanding. Previous approaches generally tackle KIE by sequence tagging, which faces difficulty to process non-flatten sequences, especially for table-text mixed documents. These approaches also suffer from the trouble of pre-defining a fixed set of labels for each type of documents, as well as the label imbalance issue. In this work, we assume Optical Character Recognition (OCR) has been applied to input documents, and reformulate the KIE task as a region prediction problem in the two-dimensional (2D) space given a target field. Following this new setup, we develop a new KIE model named Region-based Document Understanding (RDU) that takes as input the text content and corresponding coordinates of a document, and tries to predict the result by localizing a bounding-box-like region. Our RDU first applies a layout-aware BERT equipped with a soft layout attention masking and bias mechanism to incorporate layout information into the representations. Then, a list of candidate regions is generated from the representations via a Region Proposal Module inspired by computer vision models widely applied for object detection. Finally, a Region Categorization Module and a Region Selection Module are adopted to judge whether a proposed region is valid and select the one with the largest probability from all proposed regions respectively. Experiments on four types of form-style documents show that our proposed method can achieve impressive results. In addition, our RDU model can be trained with different document types seamlessly, which is especially helpful over low-resource documents.