 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReXSonoVQA: A Video QA Benchmark for Procedure-Centric Ultrasound Understanding
Apr 14, 2026Ultrasound acquisition requires skilled probe manipulation and real-time adjustments. Vision-language models (VLMs) could enable autonomous ultrasound systems, but existing benchmarks evaluate only static images, not dynamic procedural understanding. We introduce ReXSonoVQA, a video QA benchmark with 514 video clips and 514 questions (249 MCQ, 265 free-response) targeting three competencies: Action-Goal Reasoning, Artifact Resolution & Optimization, and Procedure Context & Planning. Zero-shot evaluation of Gemini 3 Pro, Qwen3.5-397B, LLaVA-Video-72B, and Seed 2.0 Pro shows VLMs can extract some procedural information, but troubleshooting questions remain challenging with minimal gains over text-only baselines, exposing limitations in causal reasoning. ReXSonoVQA enables developing perception systems for ultrasound training, guidance, and robotic automation.
ReXVQA: A Large-scale Visual Question Answering Benchmark for Generalist Chest X-ray Understanding
Jun 04, 2025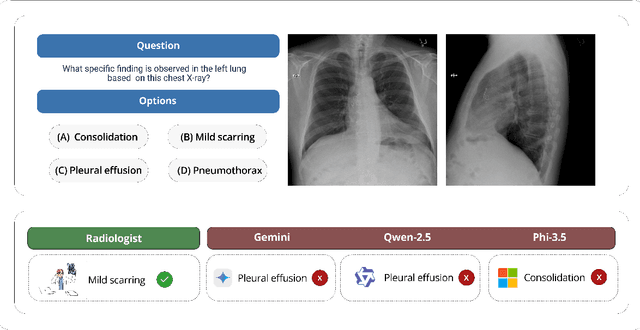
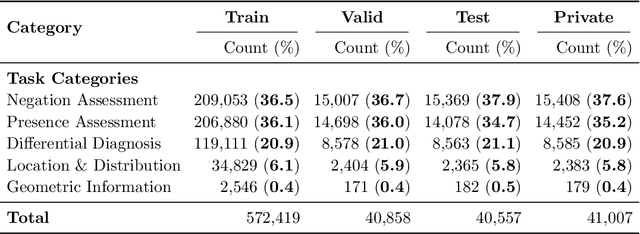
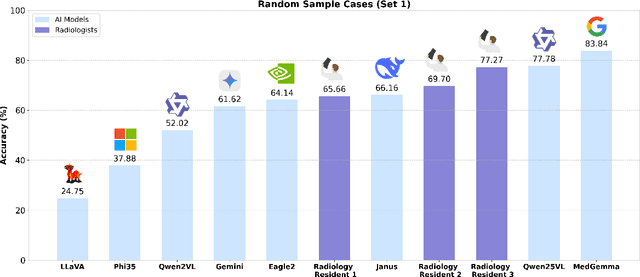
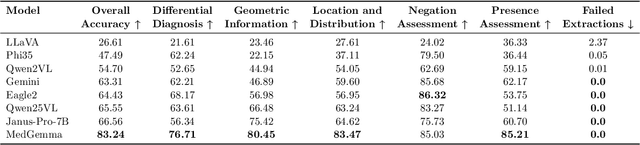
We present ReXVQA, the largest and most comprehensive benchmark for visual question answering (VQA) in chest radiology, comprising approximately 696,000 questions paired with 160,000 chest X-rays studies across training, validation, and test sets. Unlike prior efforts that rely heavily on template based queries, ReXVQA introduces a diverse and clinically authentic task suite reflecting five core radiological reasoning skills: presence assessment, location analysis, negation detection, differential diagnosis, and geometric reasoning. We evaluate eight state-of-the-art multimodal large language models, including MedGemma-4B-it, Qwen2.5-VL, Janus-Pro-7B, and Eagle2-9B. The best-performing model (MedGemma) achieves 83.24% overall accuracy. To bridge the gap between AI performance and clinical expertise, we conducted a comprehensive human reader study involving 3 radiology residents on 200 randomly sampled cases. Our evaluation demonstrates that MedGemma achieved superior performance (83.84% accuracy) compared to human readers (best radiology resident: 77.27%), representing a significant milestone where AI performance exceeds expert human evaluation on chest X-ray interpretation. The reader study reveals distinct performance patterns between AI models and human experts, with strong inter-reader agreement among radiologists while showing more variable agreement patterns between human readers and AI models. ReXVQA establishes a new standard for evaluating generalist radiological AI systems, offering public leaderboards, fine-grained evaluation splits, structured explanations, and category-level breakdowns. This benchmark lays the foundation for next-generation AI systems capable of mimicking expert-level clinical reasoning beyond narrow pathology classification. Our dataset will be open-sourced at https://huggingface.co/datasets/rajpurkarlab/ReXVQA
Text and Audio Simplification: Human vs. ChatGPT
Apr 29, 2024
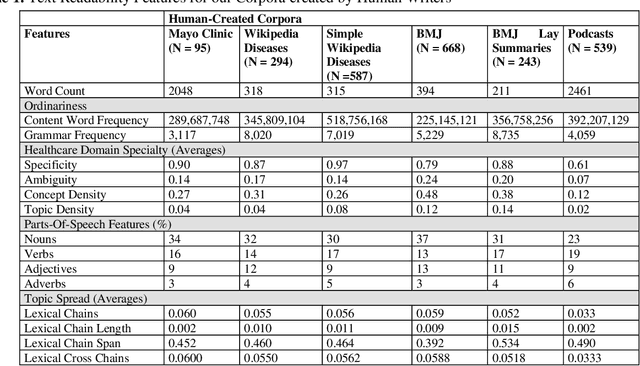
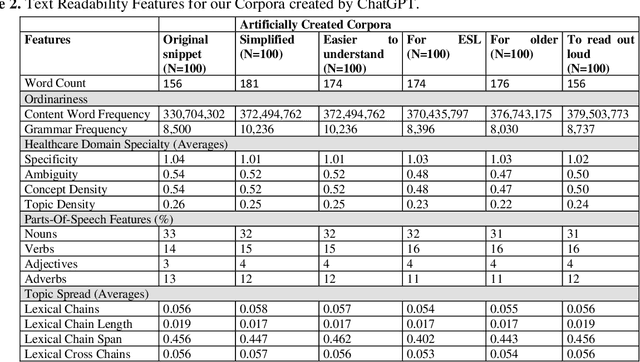
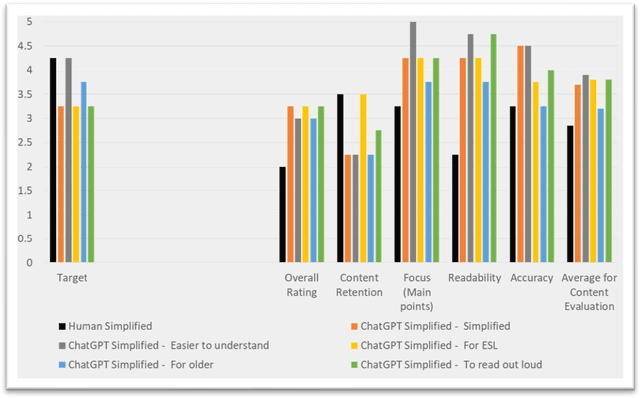
Text and audio simplification to increase information comprehension are important in healthcare. With the introduction of ChatGPT, an evaluation of its simplification performance is needed. We provide a systematic comparison of human and ChatGPT simplified texts using fourteen metrics indicative of text difficulty. We briefly introduce our online editor where these simplification tools, including ChatGPT, are available. We scored twelve corpora using our metrics: six text, one audio, and five ChatGPT simplified corpora. We then compare these corpora with texts simplified and verified in a prior user study. Finally, a medical domain expert evaluated these texts and five, new ChatGPT simplified versions. We found that simple corpora show higher similarity with the human simplified texts. ChatGPT simplification moves metrics in the right direction. The medical domain expert evaluation showed a preference for the ChatGPT style, but the text itself was rated lower for content retention.
Gemini Goes to Med School: Exploring the Capabilities of Multimodal Large Language Models on Medical Challenge Problems & Hallucinations
Feb 10, 2024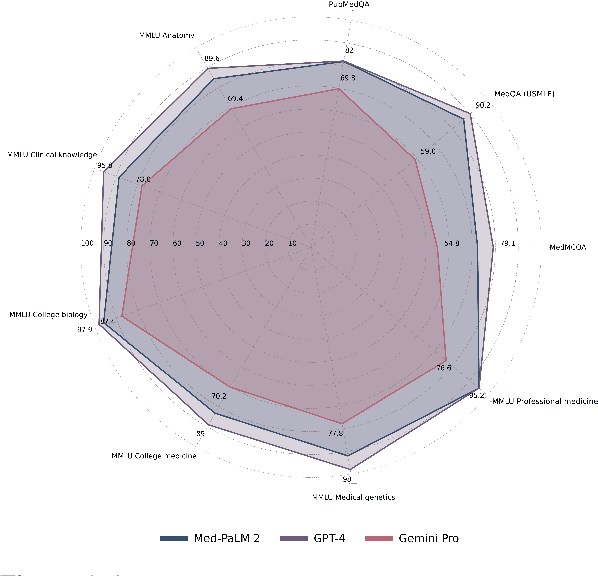

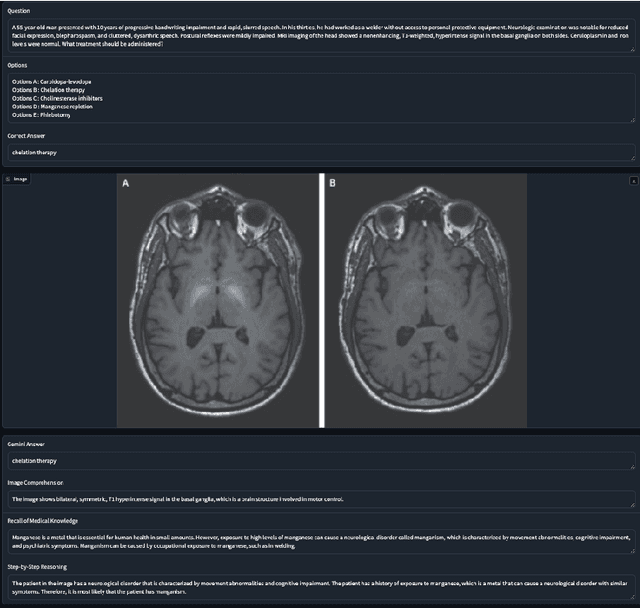
Large language models have the potential to be valuable in the healthcare industry, but it's crucial to verify their safety and effectiveness through rigorous evaluation. For this purpose, we comprehensively evaluated both open-source LLMs and Google's new multimodal LLM called Gemini across Medical reasoning, hallucination detection, and Medical Visual Question Answering tasks. While Gemini showed competence, it lagged behind state-of-the-art models like MedPaLM 2 and GPT-4 in diagnostic accuracy. Additionally, Gemini achieved an accuracy of 61.45\% on the medical VQA dataset, significantly lower than GPT-4V's score of 88\%. Our analysis revealed that Gemini is highly susceptible to hallucinations, overconfidence, and knowledge gaps, which indicate risks if deployed uncritically. We also performed a detailed analysis by medical subject and test type, providing actionable feedback for developers and clinicians. To mitigate risks, we applied prompting strategies that improved performance. Additionally, we facilitated future research and development by releasing a Python module for medical LLM evaluation and establishing a dedicated leaderboard on Hugging Face for medical domain LLMs. Python module can be found at https://github.com/promptslab/RosettaEval
CLIFT: Analysing Natural Distribution Shift on Question Answering Models in Clinical Domain
Oct 19, 2023This paper introduces a new testbed CLIFT (Clinical Shift) for the clinical domain Question-answering task. The testbed includes 7.5k high-quality question answering samples to provide a diverse and reliable benchmark. We performed a comprehensive experimental study and evaluated several QA deep-learning models under the proposed testbed. Despite impressive results on the original test set, the performance degrades when applied to new test sets, which shows the distribution shift. Our findings emphasize the need for and the potential for increasing the robustness of clinical domain models under distributional shifts. The testbed offers one way to track progress in that direction. It also highlights the necessity of adopting evaluation metrics that consider robustness to natural distribution shifts. We plan to expand the corpus by adding more samples and model results. The full paper and the updated benchmark are available at github.com/openlifescience-ai/clift
* Accepted at NeurIPS 2022 (Robustness in Sequence Modeling)
Med-HALT: Medical Domain Hallucination Test for Large Language Models
Jul 28, 2023



This research paper focuses on the challenges posed by hallucinations in large language models (LLMs), particularly in the context of the medical domain. Hallucination, wherein these models generate plausible yet unverified or incorrect information, can have serious consequences in healthcare applications. We propose a new benchmark and dataset, Med-HALT (Medical Domain Hallucination Test), designed specifically to evaluate and reduce hallucinations. Med-HALT provides a diverse multinational dataset derived from medical examinations across various countries and includes multiple innovative testing modalities. Med-HALT includes two categories of tests reasoning and memory-based hallucination tests, designed to assess LLMs's problem-solving and information retrieval abilities. Our study evaluated leading LLMs, including Text Davinci, GPT-3.5, LlaMa-2, MPT, and Falcon, revealing significant differences in their performance. The paper provides detailed insights into the dataset, promoting transparency and reproducibility. Through this work, we aim to contribute to the development of safer and more reliable language models in healthcare. Our benchmark can be found at medhalt.github.io
Federated Learning for Healthcare Domain - Pipeline, Applications and Challenges
Nov 19, 2022Federated learning is the process of developing machine learning models over datasets distributed across data centers such as hospitals, clinical research labs, and mobile devices while preventing data leakage. This survey examines previous research and studies on federated learning in the healthcare sector across a range of use cases and applications. Our survey shows what challenges, methods, and applications a practitioner should be aware of in the topic of federated learning. This paper aims to lay out existing research and list the possibilities of federated learning for healthcare industries.
* ACM Transactions on Computing for Healthcare, Vol. 3, No. 4, Article 40. Publication date: October 2022
DeepParliament: A Legal domain Benchmark & Dataset for Parliament Bills Prediction
Nov 15, 2022This paper introduces DeepParliament, a legal domain Benchmark Dataset that gathers bill documents and metadata and performs various bill status classification tasks. The proposed dataset text covers a broad range of bills from 1986 to the present and contains richer information on parliament bill content. Data collection, detailed statistics and analyses are provided in the paper. Moreover, we experimented with different types of models ranging from RNN to pretrained and reported the results. We are proposing two new benchmarks: Binary and Multi-Class Bill Status classification. Models developed for bill documents and relevant supportive tasks may assist Members of Parliament (MPs), presidents, and other legal practitioners. It will help review or prioritise bills, thus speeding up the billing process, improving the quality of decisions and reducing the time consumption in both houses. Considering that the foundation of the country's democracy is Parliament and state legislatures, we anticipate that our research will be an essential addition to the Legal NLP community. This work will be the first to present a Parliament bill prediction task. In order to improve the accessibility of legal AI resources and promote reproducibility, we have made our code and dataset publicly accessible at github.com/monk1337/DeepParliament
MedMCQA : A Large-scale Multi-Subject Multi-Choice Dataset for Medical domain Question Answering
Mar 27, 2022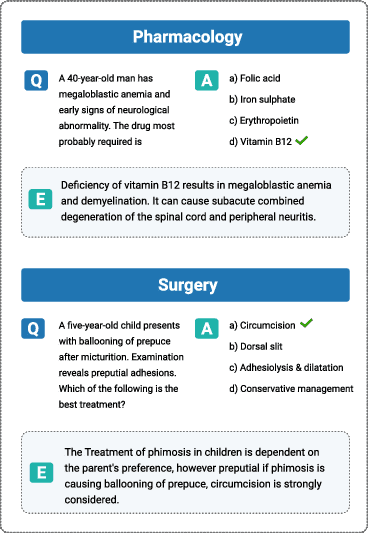

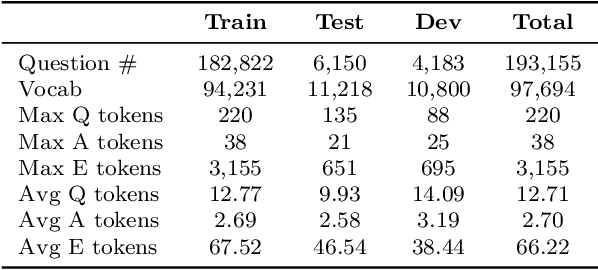
This paper introduces MedMCQA, a new large-scale, Multiple-Choice Question Answering (MCQA) dataset designed to address real-world medical entrance exam questions. More than 194k high-quality AIIMS \& NEET PG entrance exam MCQs covering 2.4k healthcare topics and 21 medical subjects are collected with an average token length of 12.77 and high topical diversity. Each sample contains a question, correct answer(s), and other options which requires a deeper language understanding as it tests the 10+ reasoning abilities of a model across a wide range of medical subjects \& topics. A detailed explanation of the solution, along with the above information, is provided in this study.
* Proceedings of Machine Learning Research (PMLR), ACM Conference on Health, Inference, and Learning (CHIL) 2022
Pay Attention to the cough: Early Diagnosis of COVID-19 using Interpretable Symptoms Embeddings with Cough Sound Signal Processing
Oct 12, 2020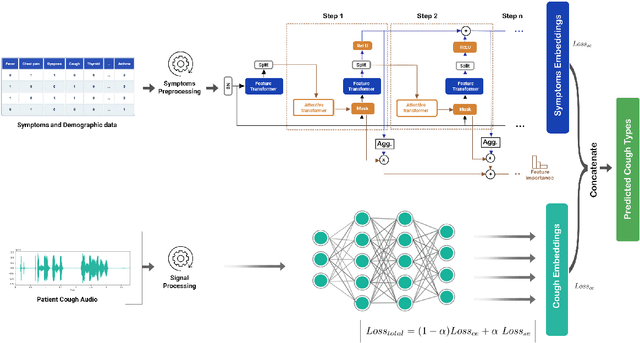
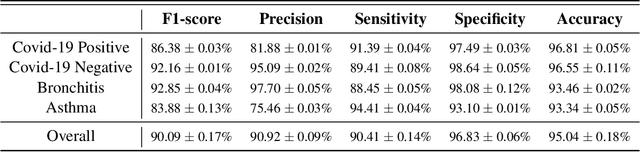
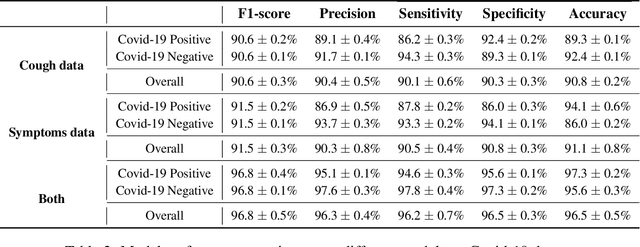
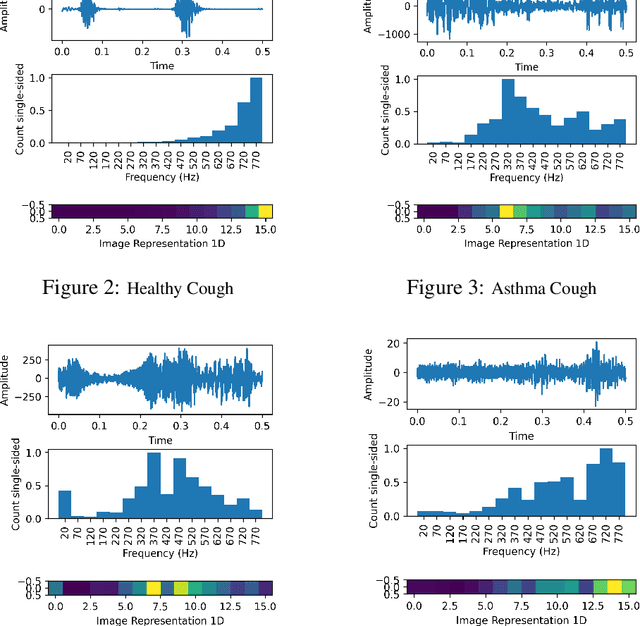
COVID-19 (coronavirus disease 2019) pandemic caused by SARS-CoV-2 has led to a treacherous and devastating catastrophe for humanity. At the time of writing, no specific antivirus drugs or vaccines are recommended to control infection transmission and spread. The current diagnosis of COVID-19 is done by Reverse-Transcription Polymer Chain Reaction (RT-PCR) testing. However, this method is expensive, time-consuming, and not easily available in straitened regions. An interpretable and COVID-19 diagnosis AI framework is devised and developed based on the cough sounds features and symptoms metadata to overcome these limitations. The proposed framework's performance was evaluated using a medical dataset containing Symptoms and Demographic data of 30000 audio segments, 328 cough sounds from 150 patients with four cough classes ( COVID-19, Asthma, Bronchitis, and Healthy). Experiments' results show that the model captures the better and robust feature embedding to distinguish between COVID-19 patient coughs and several types of non-COVID-19 coughs with higher specificity and accuracy of 95.04 $\pm$ 0.18% and 96.83$\pm$ 0.18% respectively, all the while maintaining interpretability.