 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini Goes to Med School: Exploring the Capabilities of Multimodal Large Language Models on Medical Challenge Problems & Hallucinations
Paper and Code
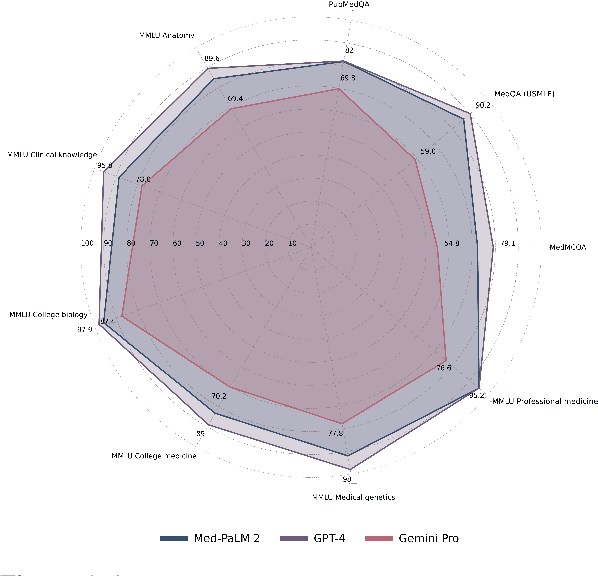

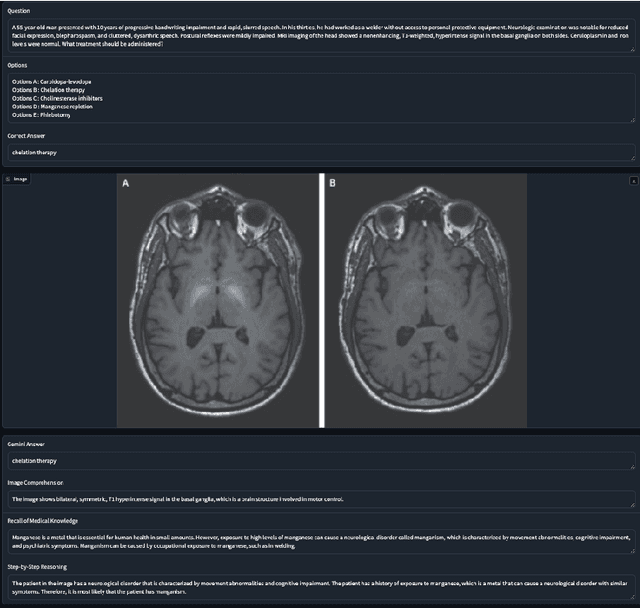
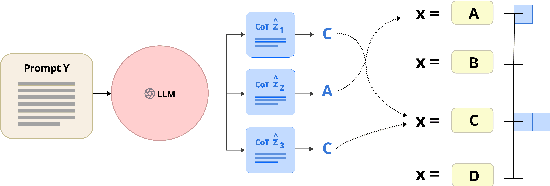
Large language models have the potential to be valuable in the healthcare industry, but it's crucial to verify their safety and effectiveness through rigorous evaluation. For this purpose, we comprehensively evaluated both open-source LLMs and Google's new multimodal LLM called Gemini across Medical reasoning, hallucination detection, and Medical Visual Question Answering tasks. While Gemini showed competence, it lagged behind state-of-the-art models like MedPaLM 2 and GPT-4 in diagnostic accuracy. Additionally, Gemini achieved an accuracy of 61.45\% on the medical VQA dataset, significantly lower than GPT-4V's score of 88\%. Our analysis revealed that Gemini is highly susceptible to hallucinations, overconfidence, and knowledge gaps, which indicate risks if deployed uncritically. We also performed a detailed analysis by medical subject and test type, providing actionable feedback for developers and clinicians. To mitigate risks, we applied prompting strategies that improved performance. Additionally, we facilitated future research and development by releasing a Python module for medical LLM evaluation and establishing a dedicated leaderboard on Hugging Face for medical domain LLMs. Python module can be found at https://github.com/promptslab/RosettaEval