 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBackdoor Adjustment of Confounding by Provenance for Robust Text Classification of Multi-institutional Clinical Notes
Oct 03, 2023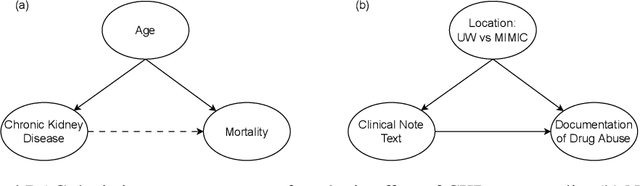

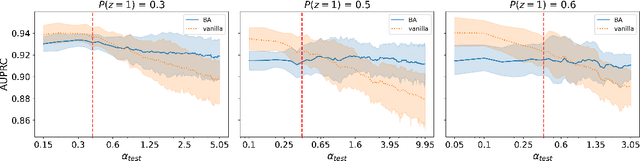
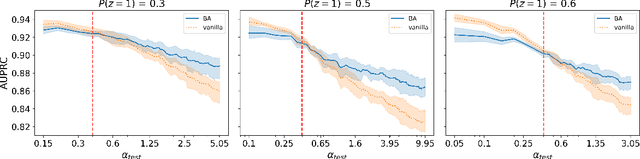
Natural Language Processing (NLP) methods have been broadly applied to clinical tasks. Machine learning and deep learning approaches have been used to improve the performance of clinical NLP. However, these approaches require sufficiently large datasets for training, and trained models have been shown to transfer poorly across sites. These issues have led to the promotion of data collection and integration across different institutions for accurate and portable models. However, this can introduce a form of bias called confounding by provenance. When source-specific data distributions differ at deployment, this may harm model performance. To address this issue, we evaluate the utility of backdoor adjustment for text classification in a multi-site dataset of clinical notes annotated for mentions of substance abuse. Using an evaluation framework devised to measure robustness to distributional shifts, we assess the utility of backdoor adjustment. Our results indicate that backdoor adjustment can effectively mitigate for confounding shift.