 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMRET: Multi-resolution Transformer for Video Quality Assessment
Paper and Code
Mar 29, 2023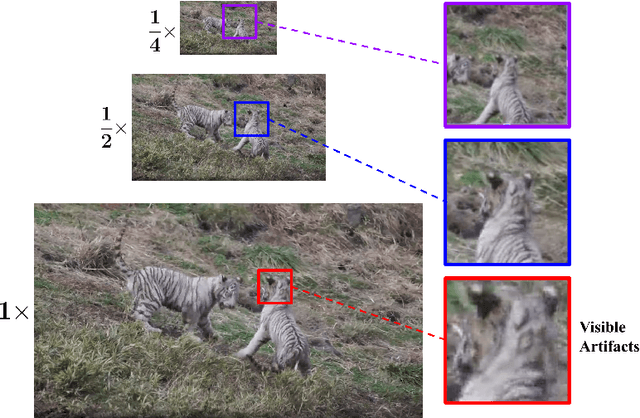
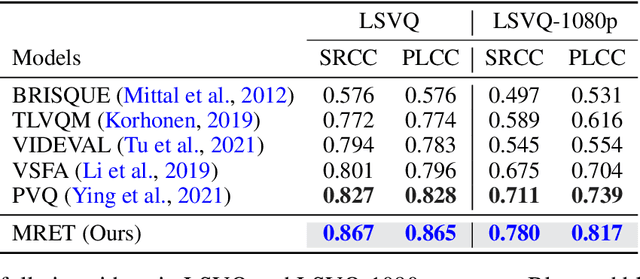
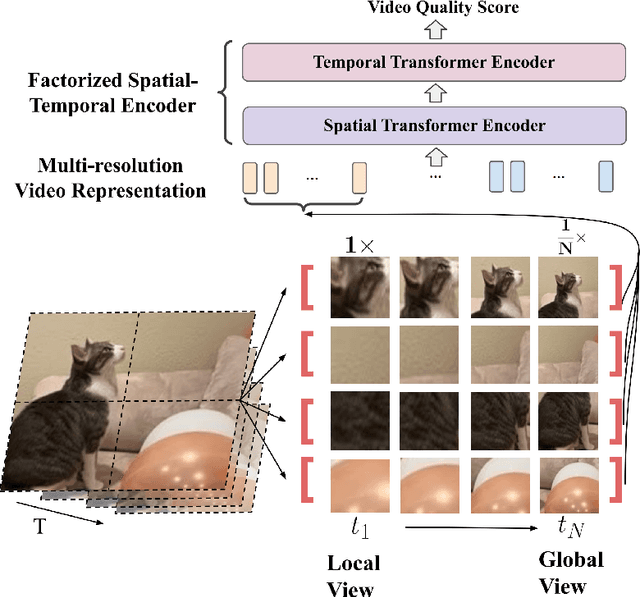
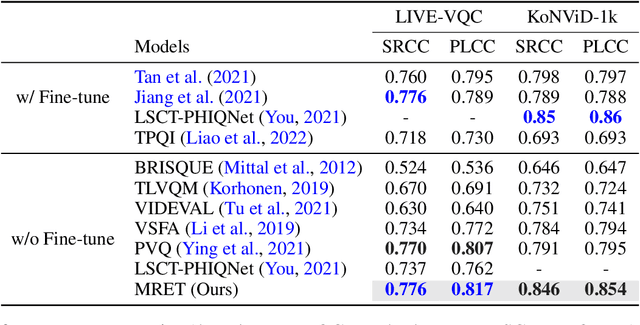
No-reference video quality assessment (NR-VQA) for user generated content (UGC) is crucial for understanding and improving visual experience. Unlike video recognition tasks, VQA tasks are sensitive to changes in input resolution. Since large amounts of UGC videos nowadays are 720p or above, the fixed and relatively small input used in conventional NR-VQA methods results in missing high-frequency details for many videos. In this paper, we propose a novel Transformer-based NR-VQA framework that preserves the high-resolution quality information. With the multi-resolution input representation and a novel multi-resolution patch sampling mechanism, our method enables a comprehensive view of both the global video composition and local high-resolution details. The proposed approach can effectively aggregate quality information across different granularities in spatial and temporal dimensions, making the model robust to input resolution variations. Our method achieves state-of-the-art performance on large-scale UGC VQA datasets LSVQ and LSVQ-1080p, and on KoNViD-1k and LIVE-VQC without fine-tuning.