 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNovel View Synthesis as Video Completion
Apr 09, 2026We tackle the problem of sparse novel view synthesis (NVS) using video diffusion models; given $K$ ($\approx 5$) multi-view images of a scene and their camera poses, we predict the view from a target camera pose. Many prior approaches leverage generative image priors encoded via diffusion models. However, models trained on single images lack multi-view knowledge. We instead argue that video models already contain implicit multi-view knowledge and so should be easier to adapt for NVS. Our key insight is to formulate sparse NVS as a low frame-rate video completion task. However, one challenge is that sparse NVS is defined over an unordered set of inputs, often too sparse to admit a meaningful order, so the models should be $\textit{invariant}$ to permutations of that input set. To this end, we present FrameCrafter, which adapts video models (naturally trained with coherent frame orderings) to permutation-invariant NVS through several architectural modifications, including per-frame latent encodings and removal of temporal positional embeddings. Our results suggest that video models can be easily trained to "forget" about time with minimal supervision, producing competitive performance on sparse-view NVS benchmarks. Project page: https://frame-crafter.github.io/
Flow3r: Factored Flow Prediction for Scalable Visual Geometry Learning
Feb 23, 2026Current feed-forward 3D/4D reconstruction systems rely on dense geometry and pose supervision -- expensive to obtain at scale and particularly scarce for dynamic real-world scenes. We present Flow3r, a framework that augments visual geometry learning with dense 2D correspondences (`flow') as supervision, enabling scalable training from unlabeled monocular videos. Our key insight is that the flow prediction module should be factored: predicting flow between two images using geometry latents from one and pose latents from the other. This factorization directly guides the learning of both scene geometry and camera motion, and naturally extends to dynamic scenes. In controlled experiments, we show that factored flow prediction outperforms alternative designs and that performance scales consistently with unlabeled data. Integrating factored flow into existing visual geometry architectures and training with ${\sim}800$K unlabeled videos, Flow3r achieves state-of-the-art results across eight benchmarks spanning static and dynamic scenes, with its largest gains on in-the-wild dynamic videos where labeled data is most scarce.
RayRoPE: Projective Ray Positional Encoding for Multi-view Attention
Jan 21, 2026We study positional encodings for multi-view transformers that process tokens from a set of posed input images, and seek a mechanism that encodes patches uniquely, allows SE(3)-invariant attention with multi-frequency similarity, and can be adaptive to the geometry of the underlying scene. We find that prior (absolute or relative) encoding schemes for multi-view attention do not meet the above desiderata, and present RayRoPE to address this gap. RayRoPE represents patch positions based on associated rays but leverages a predicted point along the ray instead of the direction for a geometry-aware encoding. To achieve SE(3) invariance, RayRoPE computes query-frame projective coordinates for computing multi-frequency similarity. Lastly, as the 'predicted' 3D point along a ray may not be precise, RayRoPE presents a mechanism to analytically compute the expected position encoding under uncertainty. We validate RayRoPE on the tasks of novel-view synthesis and stereo depth estimation and show that it consistently improves over alternate position encoding schemes (e.g. 15% relative improvement on LPIPS in CO3D). We also show that RayRoPE can seamlessly incorporate RGB-D input, resulting in even larger gains over alternatives that cannot positionally encode this information.
Open-World Object Detection with Instance Representation Learning
Sep 24, 2024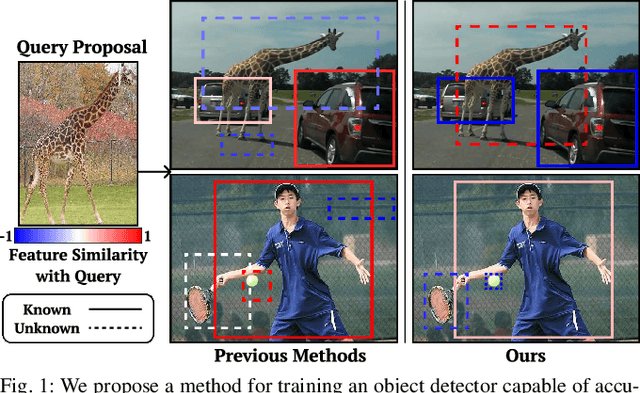
While humans naturally identify novel objects and understand their relationships, deep learning-based object detectors struggle to detect and relate objects that are not observed during training. To overcome this issue, Open World Object Detection(OWOD) has been introduced to enable models to detect unknown objects in open-world scenarios. However, OWOD methods fail to capture the fine-grained relationships between detected objects, which are crucial for comprehensive scene understanding and applications such as class discovery and tracking. In this paper, we propose a method to train an object detector that can both detect novel objects and extract semantically rich features in open-world conditions by leveraging the knowledge of Vision Foundation Models(VFM). We first utilize the semantic masks from the Segment Anything Model to supervise the box regression of unknown objects, ensuring accurate localization. By transferring the instance-wise similarities obtained from the VFM features to the detector's instance embeddings, our method then learns a semantically rich feature space of these embeddings. Extensive experiments show that our method learns a robust and generalizable feature space, outperforming other OWOD-based feature extraction methods. Additionally, we demonstrate that the enhanced feature from our model increases the detector's applicability to tasks such as open-world tracking.
DA-RAW: Domain Adaptive Object Detection for Real-World Adverse Weather Conditions
Sep 15, 2023
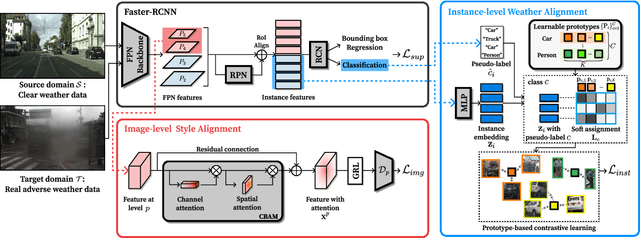

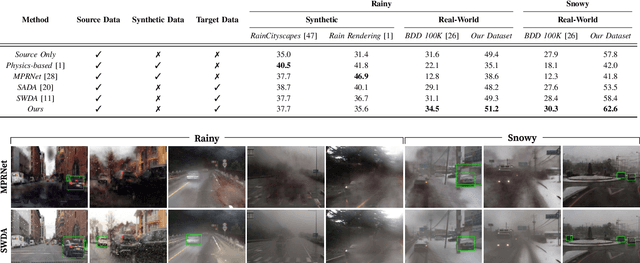
Despite the success of deep learning-based object detection methods in recent years, it is still challenging to make the object detector reliable in adverse weather conditions such as rain and snow. For the robust performance of object detectors, unsupervised domain adaptation has been utilized to adapt the detection network trained on clear weather images to adverse weather images. While previous methods do not explicitly address weather corruption during adaptation, the domain gap between clear and adverse weather can be decomposed into two factors with distinct characteristics: a style gap and a weather gap. In this paper, we present an unsupervised domain adaptation framework for object detection that can more effectively adapt to real-world environments with adverse weather conditions by addressing these two gaps separately. Our method resolves the style gap by concentrating on style-related information of high-level features using an attention module. Using self-supervised contrastive learning, our framework then reduces the weather gap and acquires instance features that are robust to weather corruption. Extensive experiments demonstrate that our method outperforms other methods for object detection in adverse weather conditions.